翻译:深入理解 Clojure Persistent Vectors 实现 Part 1
前言
这系列博客对理解 clojure vector 实现很有帮助。尝试翻译下,许久没有做这样的工作,很可能有谬误的地方,欢迎指正。
正文
你可能或多或少听说过 Clojure 的 Perisistent Vectors。它是由 Clojure 的作者 Rich Hickey 发明的(受到 Phil Bagwell 论文 Ideal Hash Trees 的影响),能做到增、改、查和 subvec (截取片段)操作近乎 O(1) 的时间复杂度,并且每个修改操作都创建一个新的 vector,而不是修改原来的。
那么,它们是如何做到这一点的呢?我将尝试通过一系列博客来解析整个实现,每篇博客关注一部分。这将是一次深入细节的解析,包括围绕在实现层面上的一些不同的、看起来略显怪异的东西。
今天,我们将学习一些基础的知识,包括更新(update)、添加(append)和出队(pop)。Clojure 的 PersistentVector 使用这些基础操作作为核心,并且采用了一些优化性能的技巧,例如 transient vector 和 tail (vector 末尾)引用。我们将在后续的博客里解析这些技巧。
基本理念
可变(mutable)的 vector 或者 ArrayList 都只是数组,根据需求自动增长或者缩小。当你接受可变性(mutability)的时候,这没有问题,一切工作的很好,但是当你想要持久性(persistence)的时候,这将是个大问题。你的修改操作将变得非常缓慢,并且耗费大量的内存,因为每次修改你都不得不总是去拷贝整个数组。如果有什么办法能够在不损失查找、更新操作性能的前提下,避免数据的重复拷贝,一切将变得非常美好。而这就是 clojure persistent vector 所实现的,在平衡有序树(balanced, ordered trees)的基础上实现。
基本的思路就是实现一个类似二叉树的数据结构。唯一的区别是它的内部节点最多只有两个子节点,并且不包含元素自身。元素是有序的,也就是最左叶子节点的元素就是第一个元素,而最后一个元素就在最右叶子节点上。暂时地,我们要求所有的叶子节点都在同一个深度上(注释1)。作为例子,我们看看下面这棵树:它包括 0 -8 范围的整数,0 在第一个位置,8 在最后面。数字 9 表示 vector 的大小:
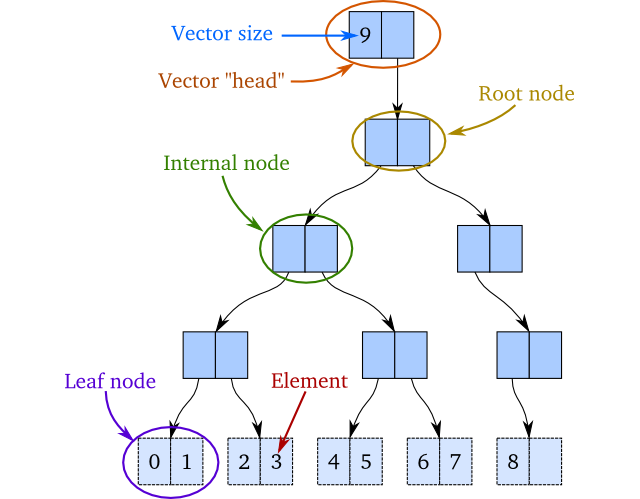
如果我们想添加一个新的元素到 vector 末尾,并且假设 vector 还是可变的(mutable),我们将 9 插入到最右的叶子节点,如图:
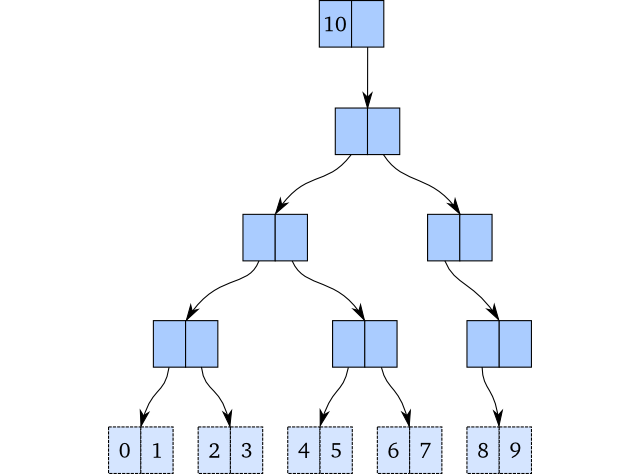
但是问题在这里:如果我们希望 vector 是不可变的,也就是持久(persistent)的时候,这显然行不通,因为我们想做的是去更新一个元素!我们必须拷贝整个数据结构,或者至少是部分。
为了在保证持久性的前提下,最小化数据拷贝的代价,我们将做路径拷贝:我们把下达(down to)将要修改或者插入的值的路径上的所有节点拷贝,并在到达底部的时候使用新值替换原来的。下面是一个多次插入新元素的例子。一个 7 个元素的 vector 和一个 10 个元素的 vector 共享了结构:
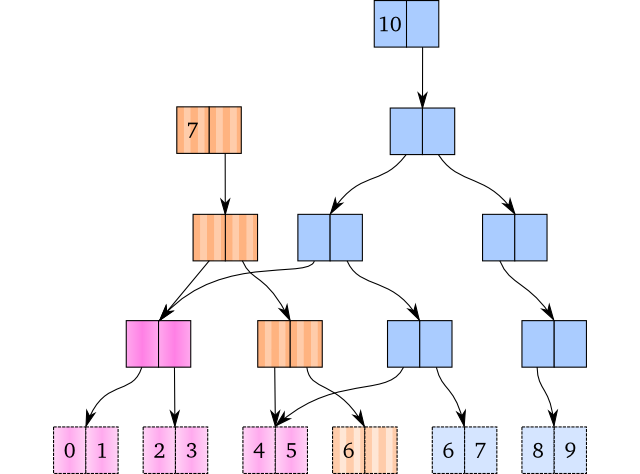
粉色的节点在两个 vector 之间共享,同时棕色和蓝色是分隔的部分。其他没有显示在这里的 vector 可能也跟这些 vector 共享一些节点。
更新(Update)
最容易理解的『修改』操作可能是更新或者替换 vector 中的值,所以我们将先解释下更新是如何工作。在 Clojure 里,更新 vector 对应着 assoc ,或者 update-in/update。
为了更新一个元素,我们需要往下遍历树,去往元素所在的叶子节点,向下遍历的过程中,我们同时拷贝路径上的节点来保证持久性。当我们向下到达元素所在叶子节点的时候,我们拷贝该叶子节点并替换成我们想要的新值。最后返回一个新的 vector,带着被修改的路径。
看一个例子,假设我们要在一个 0 至 8 的 vector 上执行 assoc 操作:
(def brown [0 1 2 3 4 5 6 7 8])
(def blue (assoc brown 5 'beef))
blue (蓝色部分)这个 vector 包含了被拷贝的路径,内部结构展示如下:
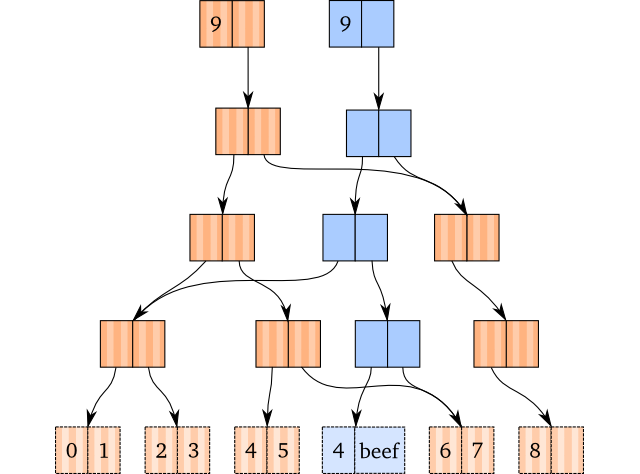
这里假定了我们知道如何找到要更新的叶子节点,看起来非常容易(我们将在这个系列的后续部分介绍如何找到这条到达目标索引位置的路径)。
添加(Append)
添加(在末尾位置插入新元素)跟更新没有太大区别,除了一些我们为了保存新值而需要新增节点的边缘情况,本质上有三种情况:
- 在最右叶子节点有空间可以放入新元素。
- 在根节点有空余空间,但是最右叶子节点没有。
- 在当前根节点没有足够空间。
我们将讨论这三种情况,它们的解决方案并不是很难掌握。
1: 跟 assoc 一样
无论何时,当最右叶子节点有空余位置的时候,插入一个新元素就跟执行 assoc 一样:拷贝向下遍历的路径,在新创建的叶子节点上,将值存入最右元素的右边。
以 (conj [0 1 2 3 4] 5) 为例子来说明,添加新元素之后的内部结构如下,蓝色是新的 vector,棕色是原有的:
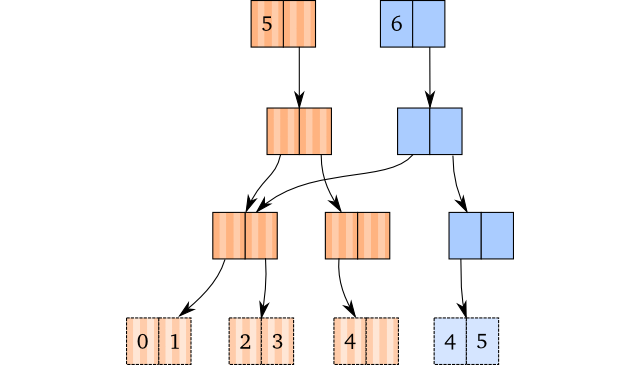
仅此而已,没有什么神奇的,只是路径拷贝和发生在叶子节点的插入操作。
2: 需要的时候创建节点
同样,如果最右叶子节点没有空余的位置怎么办?庆幸地是,我们永远不会终结于一个错误的叶子节点的位置:我们总是能找到正确的路径遍历到正确的叶子节点。
相反,我们认识到,其实是我们想要到达的节点还不存在(指针是 null)。当节点还不存在的时候,我们可以创建一个并且将它作为要拷贝的节点。
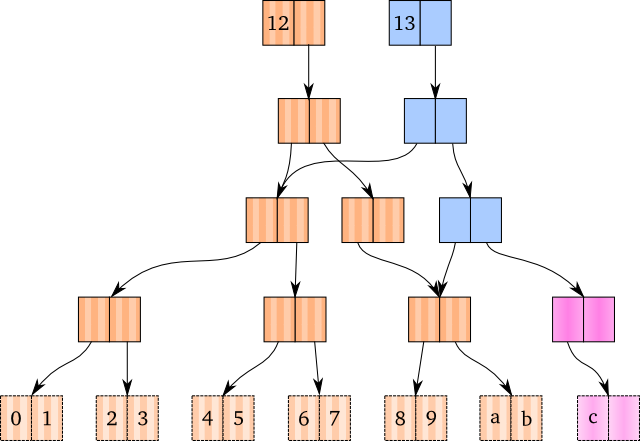
在上面的图中,粉色的是新创建的节点,蓝色的节点是我们拷贝的节点。
3: 根节点溢出
最后一种情况是根节点溢出。这发生在当前根节点对应的这棵树已经容纳不了更多新元素的时候(译者注:也就是树『满』了)。
处理这种情况也不难理解:我们创建一个新的根节点,并将老的根节点设置为新节点的第一个元素。自此以后,我们新建节点的操作就跟前面的方法一样。下面例子中紫色的是新的根节点,新创建的节点是粉色的。
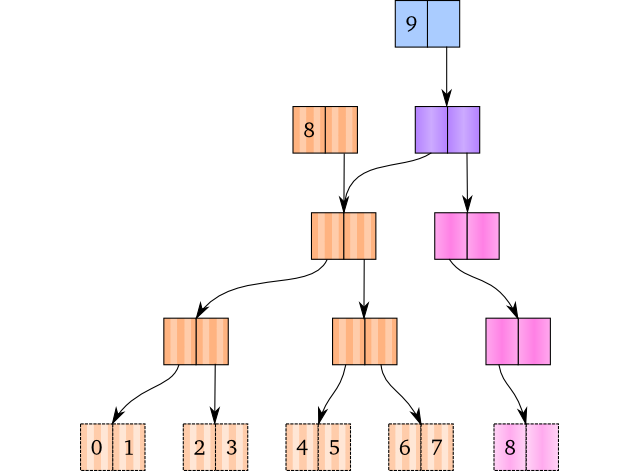
译者注:同时树的深度增加了一层。
解决问题是一回事,但是判断这一问题何时发生也同样重要,幸运的是这也很容易。当它是一棵二叉树的时候,(根节点溢出)发生在原有 vector 的大小是 2 的次幂的时候。更一般地讲,一个 n 叉树构成的 vector,当它的大小是 n 的次幂时, 根节点就会在新增元素的时候溢出。
出队(Pop)
出队(移除 vector 最后一个元素)也同样不难掌握。出队类似添加,也面临三种情况:
- 最右叶子节点包含了多于一个的元素。
- 最后叶子节点只包含了一个元素(出队后将为 0 个元素)。
- 出队后,根节点只包含了一个元素。
本质上,他们只是前面添加部分所描述的三种情况的复原,都不是非常复杂。
1: dissoc
再次,我们面临的情况跟我们更新一个 vector 类似:我们拷贝了遍历到最右叶子节点的路径,删除这个节点上的最右元素。因为最右叶子节点包含了多于一个的元素,所以移除该节点的最右元素后至少还保留了一个元素,我们不需要再做任何额外的事情。
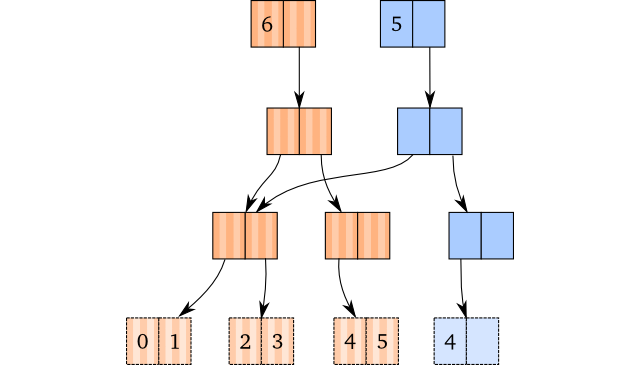
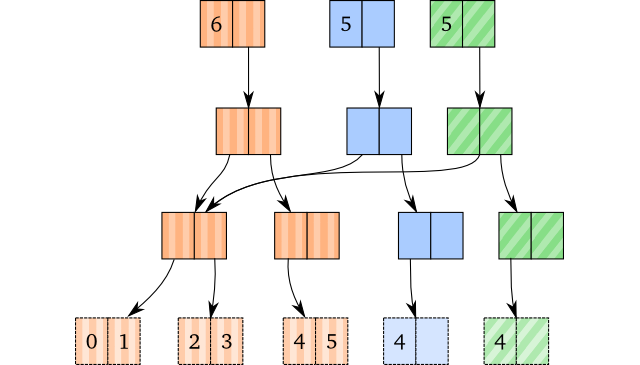
需要牢记在心的是,对一个 vector 做多次出队操作并不会得到『同一个』(identical) vector:他们是相等的(equal),但是并不共享同一个根节点,例如:
(def brown [0 1 2 3 4 5])
(def blue (pop brown))
(def green (pop brown))
将会形成下面的内部结构:
2: 移除空节点
无论何时当你遇到叶子节点只有一个元素的时候,你需要一些不同的处理。不惜任何代价,我们都想要避免在树里面出现空节点。所以一旦发现一个空节点,我们替代地返回一个 null。它的父节点将会包含一个 null 指针,而不是一个指向空节点的指针。

在上图里,棕色的 vector 是原来的,蓝色的是出队后的新 vector。
不幸地是,跟移除叶子节点上的元素相比,这并不简单。可以看到,如果我们返回一个空指针给一个节点,该节点原来只包含了一个子节点,我们必须将子节点转成一个空指针返还:清空一个节点的结果将向上层传播。这里要处理正确可能要一点技巧,但是本质上它只是查看下新的子节点,如果它是 null,并且预计要放在索引为 0 的位置(也就是第一个位置),这种情况我们就返回 null。
如果用 clojure 实现,它看起来是一个递归函数:
(defn node-pop [idx depth cur-node]
(let [sub-idx (calculate-subindex idx depth)]
(if (leaf-node? depth)
(if (== sub-idx 0)
nil
(copy-and-remove cur-node sub-idx))
; not leaf node
(let [child (node-pop idx (- depth 1)
(child-at cur-node sub-idx))]
(if (nil? child)
(if (== sub-idx 0)
nil
(copy-and-remove cur-node sub-idx))
(copy-and-replace cur-node sub-idx child))))))
当这样的函数实现后,节点的删除操作都已经完全兼顾到了。看下面这张图的例子,出队后的 vector(蓝色)移除了两个节点:包含 c 元素的叶子节点和它的父节点。

3: 移除根节点。
到此为止我们已经覆盖了所有情况,除了最后一种情况。在当前实现中,如果我们从一个 9 个元素 vector 里执行一次出队操作将得到下面的结果:

没错,我们将得到一个只包含了指向一个子节点的根节点。但是这个根节点没有什么用处,因为当我们要查找或者更新节点的时候,我们总是绕过这个根节点向下进入子节点。如果添加新元素,那也会创建新的根节点,因此我们更想消除这个无用的根节点。
这里做的事情可能是本篇博客最容易理解的部分:当我们执行完出队操作后,检查下根节点是不是仅包含了一个子节点(比如检查第二个子节点是不是 null)。如果是这种情况,而且根节点不是一个叶子节点,那么我们可以简单地将这个根节点替换成它的唯一子节点。
正如期望的那样,结果就是一个新的 vector(蓝色的),使用了原来 vector 的根节点的唯一子节点作为新的根节点:

译者注:树的深度也减少了一层。
O(1) != O(log n)
不少人很可能要说这个算法的时间复杂度怎么能说是 O(1)。实际上,以二叉树为例,它的复杂度应该是 O(log2 n),相对 O(1) 还是差的比较远。
尽管如此,没有人规定我们只能在每个节点保存两个子节点(通常称为分支因子)。Clojure 的 vector 每个节点包括 32 个子节点,这样做的结果是深度很小的浅树。实际上,如果 vector 的元素数量少于 10 亿个,整棵树的深度最多 6 层(log32 1000000000)。8 层深度的树可以包含 350 亿的元素,这种时候,我认为内存消耗是更严重的问题了。
为了实际说明这种区别我们看下这个例子:这里是一个包含了 14 个元素的四叉树,只有 2 层深度。如果你向上滚动鼠标看下前文包含了 13 和 12 个元素的两棵二叉树,他们都已经是 4 层深度了,比四叉树的深度多了一倍。

极浅树的后果是,我们倾向于将 Clojure vector 修改和查找操作认为近似(effectively)于常数时间,尽管理论上它们是O(log32 n)的复杂度,了解大 O 记法的朋友应该知道这等价于 O(log n),但是从营销角度,人们更喜欢加上常数因子。
继续阅读
希望本篇博客能让你更好地理解 Clojure Vector 是如何工作的,以及在更新、添加和出队这些操作背后隐含的理念,同时非正式地描述这些操作是如何做到高效的。插入和出队的更进一步的优化是可以实现的,在我写完 vector 的更多『关键』部分后,我们再来探讨这些优化。尤其是理解 tail 引用, transent vector 和 subvec 是如何工作的更有意义,在我们讨论微小实现细节之前。
系列博客的第二篇将更详细地关注分支(branching),以及如何查找元素。
[1] 你可以认为这是对路径选择的简化,虽然它同时包括了由于 JVM 自适应优化带来的对 JVM 性能的影响。我们将在后面更深入地探讨这一点。