Clojure Under a Microscope(1): Clojure 如何理解代码(上)
开篇
最近在读《Ruby Under a Microscope》(已经有中文版《Ruby 原理剖析》)。我很喜欢这本书介绍 Ruby 语言实现的方式,图文并茂,娓娓道来,不是特别深入,但是给你一个可以开始学习 Ruby 源码的框架和概念。
我大概在 2-3 年前开始阅读 Clojure Java 实现的源码,陆陆续续也有一些心得,想着可以在读 Ruby 这本书的时候,按照这本书的思路梳理一遍。因此就有了这第一篇: Clojure 如何理解代码。
目录:
我们抛开 leiningen 等构建工具,Clojure 唯一需要的是 JVM 和它的 jar 包,运行一段简单的 clojure 代码,可以这样:
$ java -cp clojure.jar clojure.main -e "(println (+ 2 2))"
4
clojure.main 是所有 clojure 程序的启动入口,关于启动过程,后续会有单独一篇博客来介绍。-e 用来直接执行一段传入的 clojure 代码。
当 clojure 读到 (println (+ 2 2)) 这么一行代码的时候,它看到的是一个字符串。接下来它会将这段字符串拆成一个一个字符来读入,也就是
( p r i n t l n ( + 2 2 ) )
这么一个字符列表。这是通过 java.io.PushBackReader 来完成。 Clojure 内部封装了一个 LineNumberingPushbackReader 的类继承了 PushbackReader ,并且内部封装了 Java 标准库的 LineNumberReader 来支持记录代码行列号(为了调试、报错、记录元信息等目的),并且最重要的是支持字符的回退(unread),它可以将读出来的字符『吐』回去,留待下次再读。内部其实就是一个回退字符缓冲区。
我们来试试:
(def r
(-> "(println (+ 2 2))"
(java.io.StringReader.)
(clojure.lang.LineNumberingPushbackReader.)))
(.read r) ; => 40 '('
(.read r) ; => 112 'p'
(.read r) ; => 114 'r'
(.unread r 114) ; 『吐』回 'r'
(.read r) ; => 114 'r'
(.read r) ; => 105 'i'
(.getLineNumber r) ; 获取行号,从 1 开始
(.getColumnNumber r) ; 获取列号,从 0 开始
......
read 返回的的是字符串的整数编码(0 - 65535),Clojure 默认使用的是 UTF-8 编码。查看一个字符的整数编码可以 int 强制转换:
(int \() ; => 40
(int \你) ; => 20320
上面的例子中我们 unread 了 114(也就是字符 ‘r’),然后下次调用 read,返回的仍然是 114。Clojure 的词法解析需要依赖这个回退功能。
此外还可以通过 getLineNumber 和 getColumnNumber 获取代码的行号和列号。这个行列信息最终会在 Clojure 对象的 metadata 里,比如我们看下 + 这个函数的行列信息:
user=> (select-keys (meta #'clojure.core/+) [:column :line :file])
{:column 1, :line 965, :file "clojure/core.clj"}
单个字符是没有意义,接下来,Clojure 需要理解这些字符组成的字符串是个什么东西,理解了之后才能去执行求值。
这个『东西』,在 Clojure 里定义为 form。form 其实不是 clojure 特有的概念,而应该说是 lisp 系的语言都有一个概念。form 该怎么理解呢? 粗糙地理解,它是 Clojure 的对象,对应了一种 clojure 数据类型。更精确地说,form 是一个可以被正常求值的『程序单元』。
form 可以是:
- Literals 字面量,比如字符、字符串、数字、nil、true/false 布尔值等等。
- Symbol 符号,可以先简单地理解成类似 Java 的变量名称 identifier。
- Lists 括号括起来的列表,如
(a b c)。 - Vectors 这是 clojure 有别于其他 lisp 方言的地方,中括号括起来的列表
[1 2 3] - Maps 散列表
{:a 1 :b 2}。 - Sets/Map namespace(1.9 新增)、deftype、defrecord 等其他类型。
那么 Clojure 是怎么将上面 reader 读到的字符流理解成 form 的呢?这是通过 LispReader 来完成,他负责将字符流解析成 form。我们尝试调用它的 read 方法来读取下 "(println (+ 2 2))",看看结果是什么:
(def r
(-> "(println (+ 2 2))"
(java.io.StringReader.)
(clojure.lang.LineNumberingPushbackReader.)))
(def form (clojure.lang.LispReader/read r nil))
查看下 form:
user=> form
(println (+ 2 2))
user=> (class form)
clojure.lang.PersistentList
这个 form 的『样子』和它的文本字符串是一模一样的 (println (+ 2 2)),可是它不是字符串了,而是一个 List —— Clojure 的数据结构也是最重要的数据结构。这个一模一样就是所谓的同像性,也就是 Homoiconicity。因为 form 其实就是 AST,(println (+ 2 2)) 是一个层次的嵌套结构,转换成树形如下:
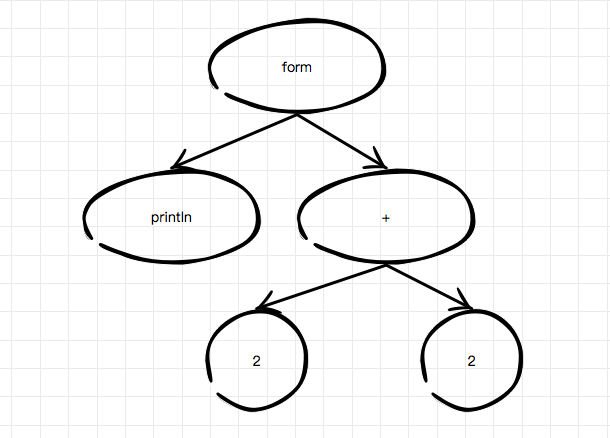
对应的刚好也是语法树,那么同像性就赋予我们操作这棵语法树的能力,因为它本质上就是一个普通的 Clojure 『对象』,也就是 form。我们可以随心所欲的操作这个 form,这也是 Clojure 强大的元编程能力的基础。
如果对应到编译原理, LispReader 不仅是 Lexer,同时也是 Parser。除了读取解析出词法单元之外,还会检查读取的结果是否是一个合法的可以被求值的 form,比如我们故意少一个括号:
user=> (read-string "(+ 1 2")
RuntimeException EOF while reading clojure.lang.Util.runtimeException (Util.java:221)
read-string 和另一个函数 read 最终调用的还是 LispReader,因为少了个括号,它会报错,这不是一个合法的 form。
编译器可以多遍扫描源码,做分词、解析、优化等等工作。那么 Clojure 编译器是几遍?
严格来讲, Clojure 的编译器是 two-pass 的,但是很多情况下都是 one-pass 的。
但是 pass 这个概念在 clojure 里不是特别合适,按照 Rich Hickey 的答复,Clojure 的编译器更多是按照一个一个编译单元来描述更合适。每个单元是一个顶层(toplevel) form。
比如你有一个 clojure 代码文件:
(def a 1)
(def b 2)
(println (+ 1 2))
clojure 编译器会认为这里有三个顶层编译单元,分别是 (def a 1),(def b 2) 和 (println (+ 1 2)),这三个编译单元都是最顶层的 form,它们会按照在文件中的出现顺序一一编译。
正因为编译单元要按照这个顺序,因此其实 clojure 不支持循环引用,或者前向查找(但是特别提供了 declare):
(def b 2)
(println (+ a b))
第二个 form 将报错,因为找不到 a:
Unable to resolve symbol: a in this context
请注意,前向查找跟多少遍扫描没有关系,一遍扫描也可以实现前向查找。Clojure 这里的选择是基于两个理由:编译性能和名称冲突考虑。参见这个 YC 上的回复。
LispReader 的实现是一个典型的递归下推机,往前读一个字符,根据这个字符的类型通过一系列 if 语句判断要执行哪一段解析,完整代码在 github,核心的循环代码精简如下,并加上注释:
for(; ;){
//读取到一个 List,返回。
if(pendingForms instanceof List && !((List)pendingForms).isEmpty())
return ((List)pendingForms).remove(0);
//读一个字符
int ch = read1(r);
//跳过空白,注意,逗号也被认为是空白
while(isWhitespace(ch))
ch = read1(r);
//读到末尾
if(ch == -1)
{
if(eofIsError)
throw Util.runtimeException("EOF while reading");
return eofValue;
}
//读到设定的返回字符,提前返回。
if(returnOn != null && (returnOn.charValue() == ch)) {
return returnOnValue;
}
//可能是数字
if(Character.isDigit(ch))
{
Object n = readNumber(r, (char) ch);
return n;
}
//根据字符,查找 reader 表,走入更具体的解析
IFn macroFn = getMacro(ch);
if(macroFn != null)
{
Object ret = macroFn.invoke(r, (char) ch, opts, pendingForms);
//no op macros return the reader
if(ret == r)
continue;
return ret;
}
//如果是正负符号,进一步判断可能是数字
if(ch == '+' || ch == '-')
{
//再读一个字符
int ch2 = read1(r);
//如果是数字
if(Character.isDigit(ch2))
{
//先回退 ch2 ,继续调用 readNumber 读出数字。
unread(r, ch2);
Object n = readNumber(r, (char) ch);
return n;
}
//不是数字,回退 ch2
unread(r, ch2);
}
//读取 token,并解析
String token = readToken(r, (char) ch);
return interpretToken(token);
}
}
LispReader 维护了一个字符到 reader 的映射,专门用于读取特定的 form,也就是上面 getMacro 用到的:
static IFn[] macros = new IFn[256]; //特殊宏字符到 Reader 函数的映射
macros['"'] = new StringReader(); // 双引号开头的使用字符串Reader
macros[';'] = new CommentReader(); // 注释
macros['\''] = new WrappingReader(QUOTE); // quote
macros['@'] = new WrappingReader(DEREF);// deref符号 @
macros['^'] = new MetaReader(); //元数据
macros['`'] = new SyntaxQuoteReader(); // syntax quote
macros['~'] = new UnquoteReader(); // unquote
macros['('] = new ListReader(); //list
macros[')'] = new UnmatchedDelimiterReader(); //括号不匹配
macros['['] = new VectorReader(); //vector
macros[']'] = new UnmatchedDelimiterReader(); // 中括号不匹配
macros['{'] = new MapReader(); // map
macros['}'] = new UnmatchedDelimiterReader(); // 大括号不匹配
macros['\\'] = new CharacterReader(); //字符,如\a
macros['%'] = new ArgReader(); // 匿名函数便捷记法里的参数,如%, %1
macros['#'] = new DispatchReader(); // #下面将提到的 dispatch macro
static private IFn getMacro(int ch){
if(ch < macros.length)
return macros[ch];
return null;
}
我们先看下 ListReader,它是一个普通的 Clojure 函数,继承 AFn ,并实现了 invoke 调用方法,关于 Clojure 的对象或者说运行时模型,我们后文再谈,ListReader 核心的代码如下:
List list = readDelimitedList(')', r, true);
IObj s = (IObj) PersistentList.create(list);
return s;
调用了 readDelimitedList 获取了一个 List 列表,然后转换成 Clojure 的 PersistentList 返回。readDelimitedList 的处理也很容易理解:
//收集结果
ArrayList a = new ArrayList();
for(; ;)
{
int ch = read1(r);
//忽略空白
while(isWhitespace(ch))
ch = read1(r);
//非法终止
if(ch == -1)
{
if(firstline < 0)
throw Util.runtimeException("EOF while reading");
else
throw Util.runtimeException("EOF while reading, starting at line " + firstline);
}
//读到终止符号,也就是右括号),停止
if(ch == delim)
break;
//可能是macro fn
IFn macroFn = getMacro(ch);
if(macroFn != null)
{
Object mret = macroFn.invoke(r, (char) ch);
//no op macros return the reader
//macro fn 如果是no op,返回reader本身
if(mret != r)
//非no op,加入结果集合
a.add(mret);
}
else
{
//非macro,回退ch
unread(r, ch);
//读取object并加入结果集合
Object o = read(r, true, null, isRecursive);
//同样,根据约定,如果返回是r,表示null
if(o != r)
a.add(o);
}
}
//返回收集的结果集合
return a;
再举一个例子,MetaReader,用于读取 form 的元信息。
Clojure 可以为每个 form 附加上元信息,例如:
user=> (meta (read-string "^:private (+ 2 2)"))
{:private true}
通过 ^:private,我们给 (+ 2 2) 这个 form 设置了元信息 private=true。当 LispReader 读到 ^ 字符的时候,它从 macros 表找到 MetaReader,然后使用它来继续读取元信息:
//meta对象,可能是map,可能是symbol,也可能是字符串,例如(defn t [^"[B" bs] (String. bs))
Object meta = read(r, true, null, true);
//symbol 或者 字符串,就是简单的type hint tag
if(meta instanceof Symbol || meta instanceof String)
meta = RT.map(RT.TAG_KEY, meta);
//如果是keyword,证明是布尔值的开关变量,如 ^:dynamic ^:private
else if (meta instanceof Keyword)
meta = RT.map(meta, RT.T);
//如果连 map 都不是,那很抱歉,非法的meta数据
else if(!(meta instanceof IPersistentMap))
throw new IllegalArgumentException("Metadata must be Symbol,Keyword,String or Map");
//读取要附加元数据的目标对象
Object o = read(r, true, null, true);
if(o instanceof IMeta)
//如果可以附加,那么继续走下去
{
if(line != -1 && o instanceof ISeq)
{
//如果是ISeq,加入行号,列号
meta = ((IPersistentMap) meta).assoc(RT.LINE_KEY, line).assoc(RT.COLUMN_KEY, column);
}
if(o instanceof IReference)
{
//如果是 ref,重设 meta
((IReference)o).resetMeta((IPersistentMap) meta);
return o;
}
//增加 meta 到原有的 ometa
Object ometa = RT.meta(o);
for(ISeq s = RT.seq(meta); s != null; s = s.next()) {
IMapEntry kv = (IMapEntry) s.first();
ometa = RT.assoc(ometa, kv.getKey(), kv.getValue());
}
//关联到o
return ((IObj) o).withMeta((IPersistentMap) ometa);
}
else
//不可附加元素,抱歉,直接抛出异常
throw new IllegalArgumentException("Metadata can only be applied to IMetas");
从代码里可以看到,不是所有 form 都可以添加元信息的,只有实现 IMeta 接口的 IObj 才可以,否则将抛出异常:
user=> ^:private 3
IllegalArgumentException Metadata can only be applied to IMetas clojure.lang.LispReader$MetaReader.invoke (LispReader.java:820)
Clojure 同时还支持 # 字符开始的所谓 dispatch macros,比如正则表达式 #"abc" 或者忽略解析的 #_(form)。这部分的解析也是查表法:
dispatchMacros['^'] = new MetaReader(); //元数据,老的形式 #^
dispatchMacros['\''] = new VarReader(); //读取var,#'a,所谓var-quote
dispatchMacros['"'] = new RegexReader(); //正则,#"[a-b]"
dispatchMacros['('] = new FnReader(); //匿名函数快速记法 #(println 3)
dispatchMacros['{'] = new SetReader(); // #{1} 集合
dispatchMacros['='] = new EvalReader(); // eval reader,支持 var 和 list的eval
dispatchMacros['!'] = new CommentReader(); //注释宏, #!开头的行将被忽略
dispatchMacros['<'] = new UnreadableReader(); // #< 不可读
dispatchMacros['_'] = new DiscardReader(); //#_ 丢弃
LispReader 读到 # 字符的时候,会从 macros 表找到 DispatchReader,然后在 DispatchReader 内部继续读取一个字符,去 dispatchMacros 找到相应的 reader 进行下一步解析。
更多 Reader 源码解析,可以参考我的注解,或者自行研读。
一张图来总结本篇所介绍的内容:
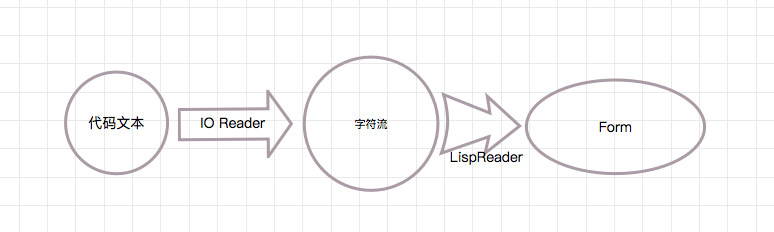
Clojure 在从文件或者其他地方读取到代码文本后,交给 IO Reader 拆分成字符,然后 LispReader 将字符流解析成可以被求值的 form。
我们前面提到 LispReader 同时是 Lexer 和 Parser,但是它并不是完整意义上的 Parser,比如它不会去检查 if 的使用是否合法:
user=> (read-string "(read-string "(if 1 2 3 4)")")
(if 1 2 3 4)
user=> (if 1 2 3 4)
CompilerException java.lang.RuntimeException: Too many arguments to if, compiling:(NO_SOURCE_PATH:93:1)
LispReader 只会检查它是否是一个合法的 form,而不会去检查它的语义是否正确,更进一步的检查需要 clojure.lang.Compiler 介入了,它会执行一个 analyze 解析过程来检查,这是下一篇要讲的内容。