Clojure Under a Microscope(1):Clojure 如何理解代码(下)
继续上篇,本篇的目的是将 parse 过程介绍完成,然后我们就可以进入编译和运行环节。
目录:
上篇在介绍 LispReader 源码核心片段的时候没有介绍最后一个比较关键的代码片段:
String token = readToken(r, (char) ch);
return interpretToken(token);
interpretToken 方法将去解析字符串 token 的含义,token 就是一个词汇单元,它的含义是什么,完全由 interpretToken 决定:
static private Object interpretToken(String s) {
if(s.equals("nil"))
{
return null;
}
else if(s.equals("true"))
{
return RT.T;
}
else if(s.equals("false"))
{
return RT.F;
}
Object ret = null;
ret = matchSymbol(s);
if(ret != null)
return ret;
throw Util.runtimeException("Invalid token: " + s);
}
代码其实很清楚,token 可能是:
- nil
- true
- false
- symbol
symbol 再次说明下,你可以暂时理解为 Java 的变量 identifier,指代某个值。
P.S. LispReader 用了相当多的相当复杂的正则表达式来匹配整数、symbol、分数等,这一块也许有性能优化的空间。
我们在上一篇提到, LispReader 它只负责解析出一个可以被求值的合法的 form,进行一些初步的语法规则检查,至于这个 form 更进一步是否符合语义,它并不关心。
比如前文举例了 (read-string "(if true 1 2 3)"),它可以被 LispReader 读出来,但是其实是不符合 if 这个 special form 的要求的,因为它只接受两个或者三个参数。
更进一步的检查是放在 clojure.lang.Compiler 中的,这个类也是 Clojure 代码编译成 JVM 所理解的字节码并交由 JVM 运行的核心。
具体地说,是 Compiler 类中的 analyze 方法,它会分析 LispReader 读出来的 form,并转化可以求值的 Expr。如图:
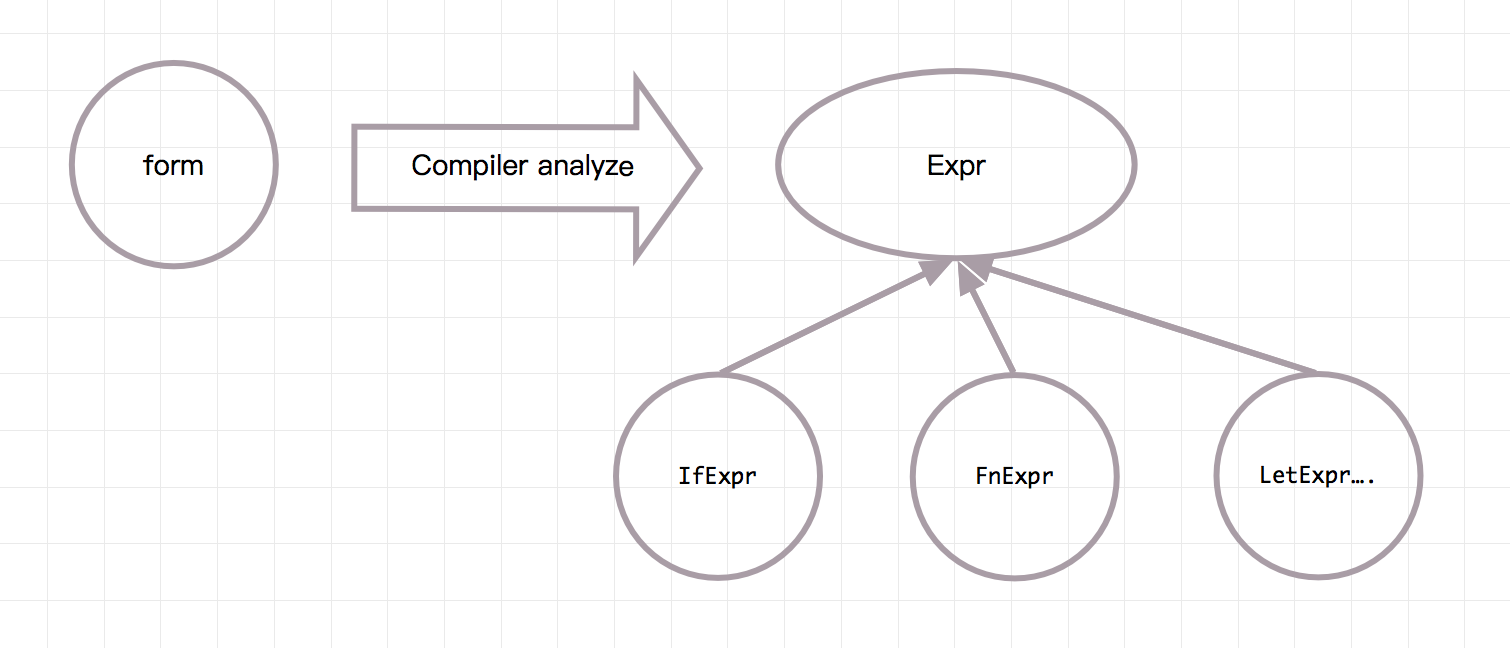
Expr 是一个 Java 接口,它有各种各样的子类,接口本身寥寥几个方法:
interface Expr{
Object eval() ;
void emit(C context, ObjExpr objx, GeneratorAdapter gen);
boolean hasJavaClass() ;
Class getJavaClass() ;
}
其中:
eval用于对自身求值,得出表达式的结果。emit用于编译,这个编译特指 Clojure 的编译,它会生成 Java 的 class 文件。hasJavaClass和getJavaClass是为了编译环节做优化引入的,暂时不聊。
关于 eval 和 emit 我们放到下一篇文章的编译再讲。这里还是聚焦在 Compiler 如何 analyze 出 Expr。
analyze 的核心仍然是一个 50 多行的 if else 派发,它会检查传入的 form 的类型,然后根据类型进入更具体的 analyze 方法,比如
(if true 1 2 3) 这是一个 Sequence,那么会进入 analyzeSeq 方法:
......
else if(form instanceof ISeq)
return analyzeSeq(context, (ISeq) form, name);
......
在 analyzeSeq 中,它会先判断 form 的第一个元素(first)是否是 fn ,也就是一个函数,如果不是,那么会去检查下是否是 specail form,这里也是一个查表法:
Object op = RT.first(form);
IParser p;
if(op.equals(FN))
return FnExpr.parse(context, form, name);
else if((p = (IParser) specials.valAt(op)) != null)
return p.parse(context, form);
else
return InvokeExpr.parse(context, form);
最后,如果不是 fn ,也不是 special forms,那么可能是一个调用(比如函数调用,宏调用,Java method 调用等),那就进入 InvokeExpr 的 parse 过程。
special forms 都定义在 specials map 里了:
static final public IPersistentMap specials = PersistentHashMap.create(
DEF, new DefExpr.Parser(),
LOOP, new LetExpr.Parser(),
RECUR, new RecurExpr.Parser(),
IF, new IfExpr.Parser(),
CASE, new CaseExpr.Parser(),
LET, new LetExpr.Parser(),
LETFN, new LetFnExpr.Parser(),
DO, new BodyExpr.Parser(),
FN, null,
QUOTE, new ConstantExpr.Parser(),
THE_VAR, new TheVarExpr.Parser(),
IMPORT, new ImportExpr.Parser(),
DOT, new HostExpr.Parser(),
ASSIGN, new AssignExpr.Parser(),
DEFTYPE, new NewInstanceExpr.DeftypeParser(),
REIFY, new NewInstanceExpr.ReifyParser(),
// TRY_FINALLY, new TryFinallyExpr.Parser(),
TRY, new TryExpr.Parser(),
THROW, new ThrowExpr.Parser(),
MONITOR_ENTER, new MonitorEnterExpr.Parser(),
MONITOR_EXIT, new MonitorExitExpr.Parser(),
// INSTANCE, new InstanceExpr.Parser(),
// IDENTICAL, new IdenticalExpr.Parser(),
//THISFN, null,
CATCH, null,
FINALLY, null,
// CLASS, new ClassExpr.Parser(),
NEW, new NewExpr.Parser(),
// UNQUOTE, null,
// UNQUOTE_SPLICING, null,
// SYNTAX_QUOTE, null,
_AMP_, null
);
可以看到核心的 special forms 其实是非常少的,所以我一直不理解被人说 clojure 语法复杂。其实它的核心语法就这么 20 几个 special forms。
每个 special form 都对应一个 IParser 的子类:
interface IParser{
Expr parse(C context, Object form) ;
}
实现其中的 parse 方法,将 form 解析成对应的 Expr 子类。if 对应的就是 IfExpr.Parser 和 IfExpr 了。
我们来画张 UML 图总结下这块结构:
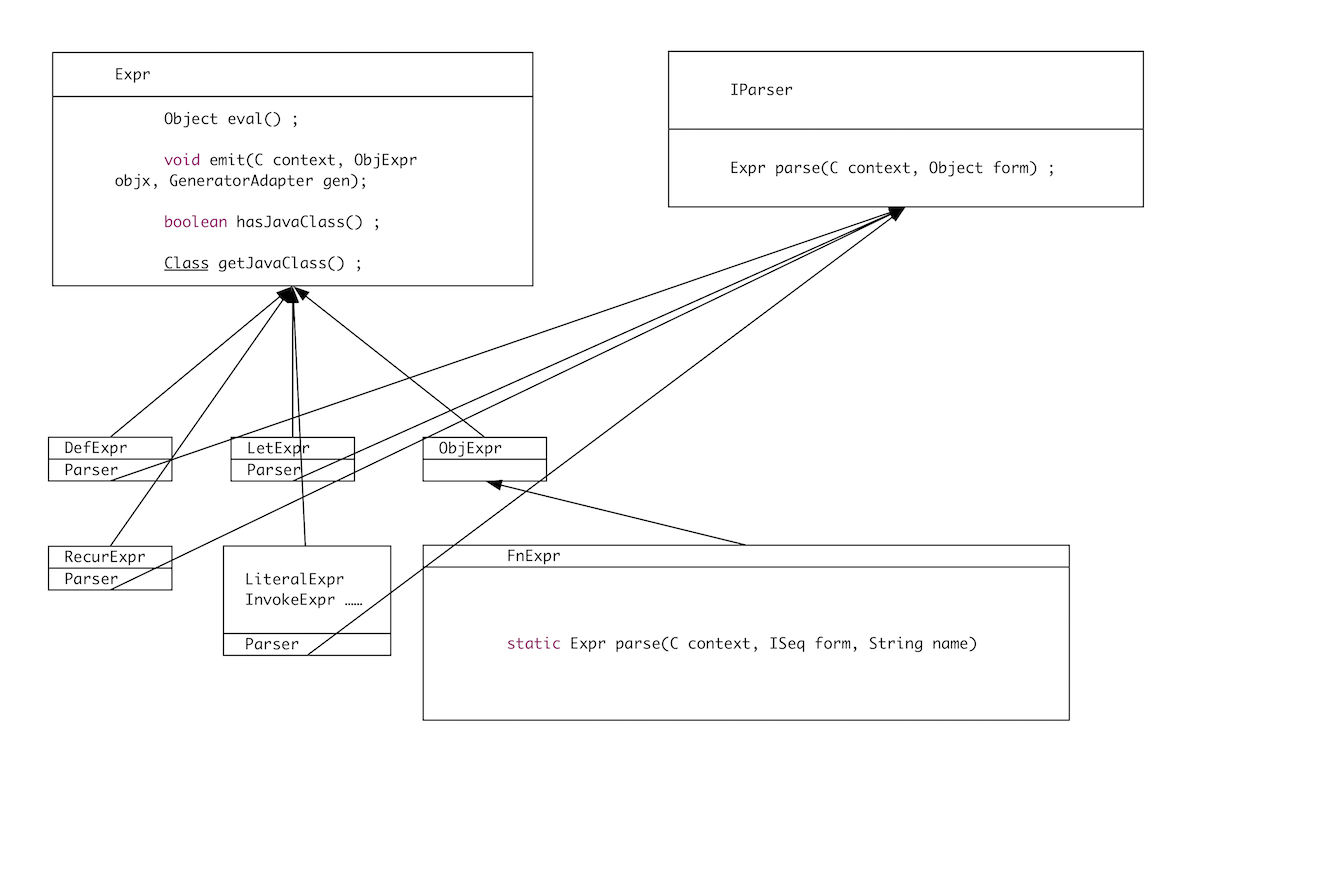
每个 Expr 子类都有个内部类 Parser,它实现了 IParser 接口的 parse 方法,然后解析出对应的外部类这个 Expr 对象。
下面我们来分析一两个 Parser。
以 IfExpr.Parser 为例子,去除一些我们暂时不关心的内容之后:
public Expr parse(C context, Object frm) {
ISeq form = (ISeq) frm;
//(if test then) or (if test then else)
if(form.count() > 4)
throw Util.runtimeException("Too many arguments to if");
else if(form.count() < 3)
throw Util.runtimeException("Too few arguments to if");
Expr testexpr = analyze(context == C.EVAL ? context : C.EXPRESSION, RT.second(form));
Expr thenexpr, elseexpr;
try {
thenexpr = analyze(context, RT.third(form));
}finally{......}
try {
elseexpr = analyze(context, RT.fourth(form));
} finally{......}
return new IfExpr(lineDeref(),
columnDeref(),
testexpr,
thenexpr,
elseexpr);
}
这逻辑实在太直白了,所以我注释都没加:
- 检查下整个 form 的元素数目是不是在 3 个或者 4 个(为什么不是 2 或者 3?因为
if本身是 form 的第一个元素)。如果参数不对,就报错。 - 调用
analyze递归分析 test 『语句』,也就是 form 的第二个元素。 - 调用
analyze继续分析 then 和 else 『语句』。 - 最后,将分析后的结果生成一个
IfExpr对象返回。
我们再来分析一个稍微复杂点的,比如 fn,fn 有两种格式:
;;定义函数,没有其他重载函数。
(fn name? [params* ] condition-map? exprs*)
;;定义函数,多个重载函数分支,每个都是 ([params* ] condition-map? exprs*) 的格式
(fn name? ([params* ] condition-map? exprs*)+)
前者也是先在 FnExpr.Parser 内转成后者的:
//now (fn [args] body...) or (fn ([args] body...) ([args2] body2...) ...)
//turn former into latter
if(RT.second(form) instanceof IPersistentVector)
form = RT.list(FN, RT.next(form));
然后对 form 做迭代,每个重载分支称为一个 FnMethod,调用 FnMethod.Parser 来解析:
for (ISeq s = RT.next(form); s != null; s = RT.next(s)) {
FnMethod f = FnMethod.parse(fn, (ISeq) RT.first(s), fn.isStatic);
if (f.isVariadic()) {
if (variadicMethod == null)
variadicMethod = f;
else
throw Util.runtimeException("Can't have more than 1 variadic overload");
}
else if (methodArray[f.reqParms.count()] == null)
methodArray[f.reqParms.count()] = f;
else
throw Util.runtimeException("Can't have 2 overloads with same arity");
if (f.prim != null)
prims.add(f.prim);
}
解析出来的 FnMethod 会根据它的参数个数加到数组 methodArray 里。这个数组的大小是 21 个,也就是说任何函数的重载分支不能超过 21 个,需要更多参数的,请使用可变参数 [& args]。
其中 variadicMethod 会指向其中的可变参数分支的 FnMethod(f.isVariadic 返回真),但是会检查这个分支的参数个数必须比其他分支的参数个数多:
for(int i = variadicMethod.reqParms.count() + 1; i <= MAX_POSITIONAL_ARITY; i++)
if(methodArray[i] != null)
throw Util.runtimeException(
"Can't have fixed arity function with more params than variadic function");
举个例子:
user=> (fn ([a] 1) ([a b c] 3) ([a & args] :variadic))
CompilerException java.lang.RuntimeException: Can't have fixed arity function with more params than variadic function
FnMethod 指代一个函数的重载分支,它的解析也很直白,先解析参数列表:
FnMethod method = new FnMethod(......);
......
PersistentVector argLocals = PersistentVector.EMPTY;
for(int i = 0; i < parms.count(); i++)
{
if(!(parms.nth(i) instanceof Symbol))
throw new IllegalArgumentException("fn params must be Symbols");
Symbol p = (Symbol) parms.nth(i);
......
argLocals = argLocals.cons(lb);
}
method.argLocals = argLocals;
参数一定是 symbol,所有参数收集到一个 PersistentVector 里。
如果有可变参数符号 &,那么就有 restParam:
static final Symbol _AMP_ = Symbol.intern("&");
......
if(p.equals(_AMP_)){
......
state = PSTATE.REST;
......
case REST:
method.restParm = lb;
然后前文提到的 isVariadic 就是判断有没有 restParm:
//是否是可变参数分支
boolean isVariadic(){
return restParm != null;
}
然后解析函数 body:
method.body = (new BodyExpr.Parser()).parse(C.RETURN, body);
return method;
解析 Body 的 BodyExpr 又是一个递归调用 analyze 的过程:
public Expr parse(C context, Object frms) {
ISeq forms = (ISeq) frms;
//可能是 (do form1 form2 ...),取 next 部分。
if(Util.equals(RT.first(forms), DO))
forms = RT.next(forms);
PersistentVector exprs = PersistentVector.EMPTY;
//遍历 body form 列表,收集结果到 exprs vector
for(; forms != null; forms = forms.next())
{
Expr e = (context != C.EVAL &&
(context == C.STATEMENT || forms.next() != null)) ?
analyze(C.STATEMENT, forms.first())
:
analyze(context, forms.first());
exprs = exprs.cons(e);
}
//如果 body 为空,返回 nil
if(exprs.count() == 0)
exprs = exprs.cons(NIL_EXPR);
// 否则返回 BodyExpr
return new BodyExpr(exprs);
}
细心的朋友可能还注意上面 FnExpr 遍历重载分支的时候有个 prims 的链表,它会将 fn.prime 不为 null 的加进去。它是干什么的呢?
if (f.prim != null)
prims.add(f.prim);
其实这里是 Clojure 编译器为了 long/double 类型的参数避免类型转化和 box/unbox 引入的性能优化。prim 就是 primitive 的意思。当参数的 type hint 包含 double 或者 long 类型的并且参数个数小于4个的时候,生成的 Java 字节码方法将直接传入 long 或者 double 原生类型参数,而不是一般的 Object 类型,避免了转型和装箱拆箱。
FnMethod 相关代码:
method.prim = primInterface(parms);
static public char classChar(Object x){
Class c = null;
if(x instanceof Class)
c = (Class) x;
else if(x instanceof Symbol)
c = primClass((Symbol) x);
if(c == null || !c.isPrimitive())
return 'O';
//如果是 long 类型,返回 L 字符
if(c == long.class)
return 'L';
// 如果是 double 类型,返回 D 字符
if(c == double.class)
return 'D';
throw new IllegalArgumentException("Only long and double primitives are supported");
}
static public String primInterface(IPersistentVector arglist) {
StringBuilder sb = new StringBuilder();
//拼接所有参数类型字符
for(int i=0;i<arglist.count();i++)
sb.append(classChar(tagOf(arglist.nth(i))));
sb.append(classChar(tagOf(arglist)));
String ret = sb.toString();
//如果包含了 D 或者 L,并且参数个数小于 4 个,就认为是一个 prim 分支。
boolean prim = ret.contains("L") || ret.contains("D");
if(prim && arglist.count() > 4)
throw new IllegalArgumentException("fns taking primitives support only 4 or fewer args");
//特殊命名
if(prim)
return "clojure.lang.IFn$" + ret;
return null;
}
Clojure 编译器会为每个函数分支都生成一个 invoke 方法。
举例来说,对于方法 (fn [^long a ^String b] :nothing),如果没有这个优化,生成的 Java 方法大概是这样:
public Object invoke(Object a, Object b){
long a = (Long) a;
String b = (String) b;
return Keyword.intern("nothing");
}
对于参数 a 来说,为了转化成 long 原生类型需要经过转型和拆箱两个调用,这对于性能敏感的场景是一个损耗。有了这个优化, invoke 方法就可以是这样:
public Object invokePrim(long a, Object b){
String b = (String) b;
return Keyword.intern("nothing");
}
有兴趣地还可以阅读下这篇博客 warn-on-boxed。这个优化对于数值计算的性能有很大作用,从测试来看,有一倍的提升。
clojure.lang.Compiler 的 analyze 进一步将 LispReader 读出来的 form 解析成了 Expr,等待进一步的求值或者编译成 Java Class 文件。analyze 过程也是一个递归下降解释器的实现,整体实现并不复杂。
结合前文和本篇博客,我们可以给 Clojure 编译器初步画一张流程图,只考虑求值过程,暂不考虑 compile 函数:
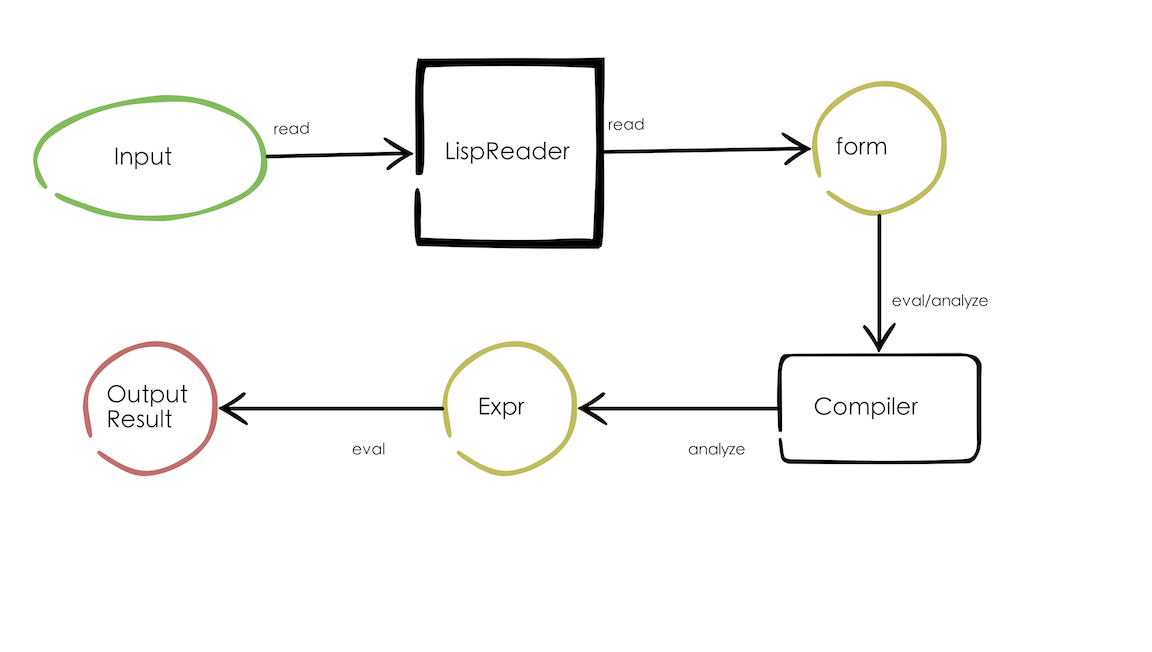
接下来,我们即将进入求值和编译环节。
最后附赠一个 Compiler 所有 Expr 子类的 UML 图(单独打开放大):