When Systems Turn Uncertain: How Datadog Sees Observability in the AI Era
Table of Contents
- Back to first principles: observability has always been a business of fighting complexity
- What AI really changes isn’t “one more thing to monitor” — it’s the nature of the system
- The second change: it’s no longer only humans who operate the system
- The third change: the “reader” of the data goes from human to model
- What gives it the standing to say all this
- A reality check: this is, after all, an investor narrative
- In closing
- References
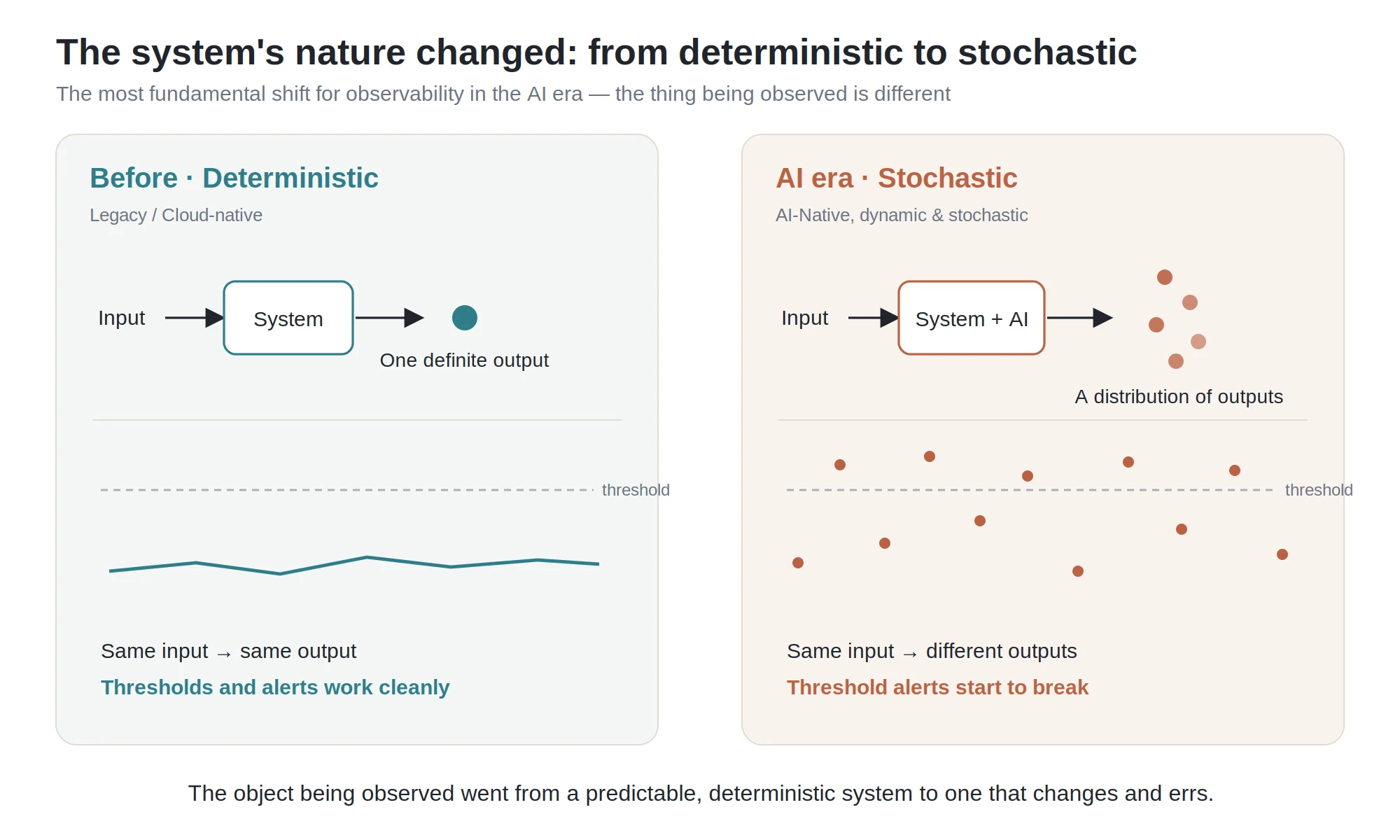
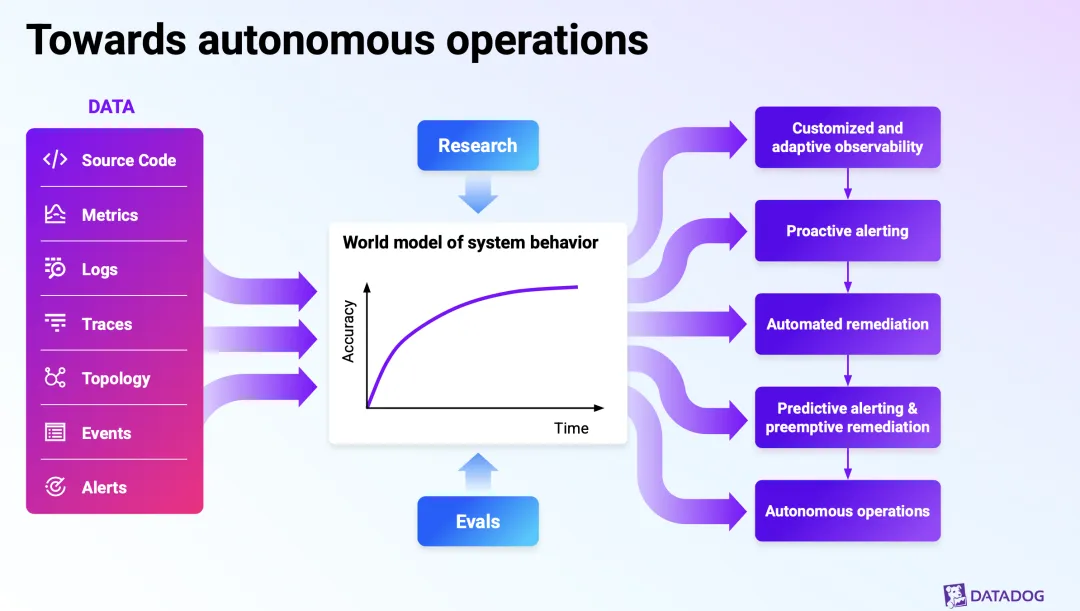
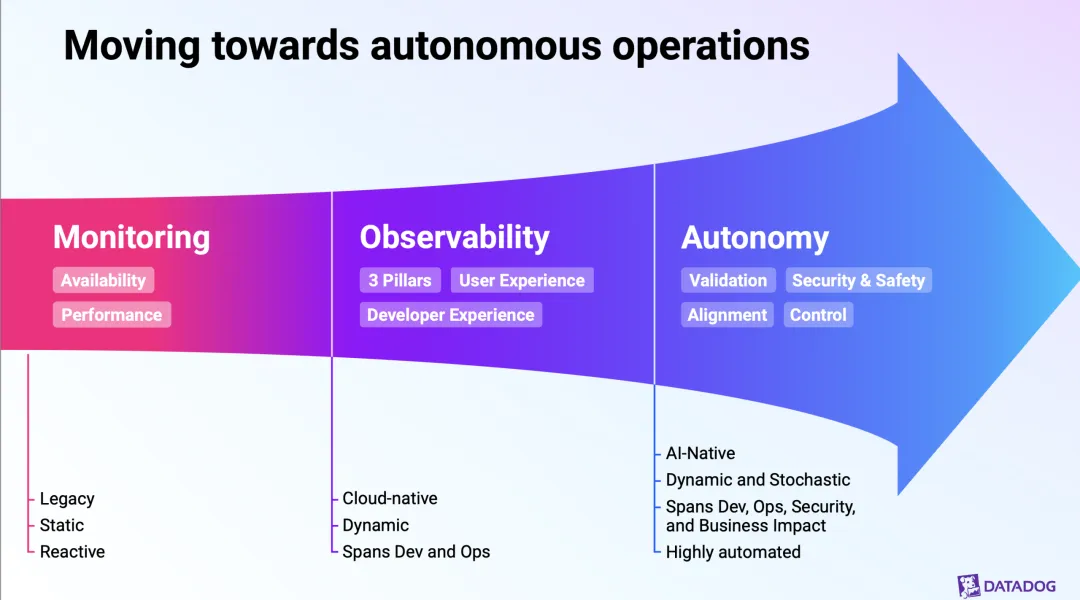
Datadog's Investor Day deck quietly redefines observability: the object of observation turns probabilistic, AI agents become operators, and the reader of the data shifts from human to model. In February 2026, Datadog held an Investor Day and put out a 200-plus-page deck. A friend shared it with me, and I went through it over the weekend with some help from AI. Most people will go straight for the numbers: revenue CAGR, margins, customer counts, that handsome free-cash-flow curve. Those matter, of course. But once I finished the deck, what I cared about more was something else: Datadog’s understanding of “observability” itself has quietly shifted. And I don’t think that shift is Datadog’s story alone. It looks more like a question the whole industry has to face in the AI era. To see what changed, you first have to know what didn’t. Observability, from day one, has fought the same thing: complexity. Twenty years ago, with one physical server and a monolith, you’d SSH in and read the logs when something broke. Then came the cloud, and a system became hundreds or thousands of auto-scaling instances, then containers, then serverless functions. The stack grew messier, releases grew more frequent, and the people involved expanded from ops alone to dev, security, even business. Systems went from “static” to “dynamic,” from “isolated” to “tangled together.” It’s exactly this complexity that gave rise to the observability we know today. The three pillars (metrics, logs, and traces) are essentially a toolkit for helping people see, locate, and fix problems inside a dynamic system they can’t fully see. So hold on to this through-line: the value of observability has always been anchored to how much complexity it helps people fight. Everything in Datadog’s pitch grows out of this one line. A lot of people’s first reaction to “observability in the AI era” is: it’s just a few more things to monitor, right? GPUs, LLM calls, agent behavior. That’s not wrong, but it stops at the surface. What Datadog understands is one layer deeper. It draws the evolution of systems in three stages: We got used to “dynamic” long ago; cloud-native spent the last decade-plus teaching us how to observe a constantly changing system. But “stochastic” is the new thing. It’s the word the deck uses, and to me it’s the single most important word in the whole thing. stochastic /stəˈkæstɪk/ adjective: random; probabilistic; governed by chance. That is: the outcome of a process, model, or system isn’t fully determined — it carries randomness and usually has to be described in terms of probability. What does that mean? However dynamic a traditional system is, its behavior is basically deterministic: the same input gives the same output, so you can set thresholds and rules, fire an alert when they’re crossed, and send a human to look. That paradigm works precisely because the system is assumed to be predictable. An AI system isn’t. The same prompt can produce a different answer this time than next; an agent facing the same situation can take a completely different path. The system goes from “deterministic” to “probabilistic.” And just like that, the old “set a threshold, wait for the alert, go dig” logic starts to break down. You can’t draw a clean red line around something that’s fundamentally random. The question observability has to answer shifts from “did this metric cross a threshold” to “this system that changes on its own and can get things wrong: what state is it actually in right now, and can I trust it?” This is the first and most fundamental turn in thinking: the object being observed went from a deterministic system to a probabilistic one. The tool has to follow the nature of its object, so observability itself has to be rebuilt. p.s. Isn’t this a little like leaving a macroscopic system and stepping into the quantum mechanics of the microscopic world? Datadog has long measured complexity by “how many people are involved”: from ops only, to dev plus ops, to security and business joining in. This time it added a new role at the end of that line: AI agents. In short, the things that did the work and got blamed when something broke used to be humans and code. Now there’s a new kind of “operator”: it calls tools on its own, consumes resources, makes decisions, and can also be hit by prompt injection or leak data. So observability’s boundary gets pushed again. You no longer observe just infrastructure and applications; you observe these AI agents themselves: what tools they’re calling, whether they’ve overstepped, whether they’ve been fooled, whether their behavior is still inside the bounds you set. (For more, see a piece I wrote: “Agent Observability: The Old Bottle Still Works, But You Have to Fill It With New Wine.”) Datadog has laid down a whole stack for this: LLM observability, an agent console, and security built specifically for AI, such as prompt-injection protection, sensitive-data redaction, and AI security posture management. One signal: it says the volume of data sent to LLM observability has grown more than tenfold. Put differently, an AI agent is both a new object to observe and a new operating subject. Once machines start operating systems on our behalf, “keeping an eye on the machine” becomes a hard requirement in itself. The first two changes are about what you observe; this one is about who you observe it for. The old chain was clear: the system emits metrics, logs, and traces; they pool into a dashboard; a human sits in front of the screen, reads the charts, decides, and fixes. The end consumer of the data was the human. Datadog’s read now is this: the primary reader of the data is shifting from human to model. Its pitch is to take source code, metrics, logs, traces, topology, events, and alerts, and use them to feed a “world model of system behavior,” then layer continuous evaluation on top so the system climbs a ladder: adaptive observability → proactive alerting → automated remediation → predictive alerting and preemptive remediation → autonomous operations. If you pull out its core slogan, it’s that three-stage progression: Monitoring → Observability → Autonomy Note that the last one, Autonomy, is newly added. In other words, the ultimate goal of observability is shifting from “help people solve problems faster” to “let the system solve problems by itself,” with humans stepping back into validation, alignment, and control. Underneath all this is a plain loop: when the system gets too complex for people to keep up with, when its behavior turns probabilistic, and when the things operating it now include a pile of AI agents, the “humans staring at dashboards” path simply stops working — physically. To fight the complexity AI brings, in the end you can only use AI. So Datadog redefines observability from “a diagnostic tool for humans” into “the foundation for autonomous operations.” This vision isn’t all slides. Datadog has already shipped the first AI on-call engineer, Bits AI SRE: it investigates problems on its own, generates and verifies multiple hypotheses in parallel, and surfaces a root cause backed by evidence. By its own account, it has run more than 100,000 investigations since launch, and more than 2,000 customers used it in the past month alone. Anyone can paint a vision; the question is on what basis. Datadog’s basis lands on data. It stresses that its distinctive edge is three things stacked together: a massive volume of operational data (trillions of datapoints per hour), in-house foundation models, and deep operational-domain expertise. It actually trained a model, called Toto, its first in-house time-series foundation model, trained on more than a trillion datapoints, roughly 750 billion of them unique to Datadog, four to ten times the data of other leading time-series models. The model ships as open weights, has been downloaded more than nine million times on Hugging Face, and cost only about $750K to train. From there it makes an argument I find pretty persuasive; call it “small-model economics.” General-purpose frontier models can reach very high accuracy, but they’re too expensive. A small, specialized model aimed at the single vertical of observability can get close to the same accuracy at far lower cost. This is really a head-on answer to a sharp question: with GPT and Claude already out there, why would you, Datadog, build your own model? Its answer: general intelligence doesn’t solve the cost equation for my use case, and the operational data I uniquely hold is exactly the moat that stops others from training a specialized model like this. Put the whole logic together and you get a data flywheel: the platform accumulates massive operational data → trains specialized models and AI agents → the agents help customers solve problems faster and automate operations → customers go deeper and run more AI applications → which generates even more data that needs observing. Data feeds the models, the models create value, and the value brings in more data. Datadog’s core competitiveness, too, will keep coming from data over the long run. Time to tap the brakes. This is an Investor Day talk, and its purpose is to tell a story people will want to hold for the long term. The deck leans heavily on “illustrative” diagrams and anonymous customer testimonials. That “autonomous operations” ladder is, for now, more vision than something already running in production, and every “forward-looking” claim in it deserves a discount. Numbers like a customer’s “10x fewer incidents, $11M saved” — take the direction, not the conclusion, and don’t read them as already broadly realized. And the more polished and self-consistent a narrative is, the more you should watch for it making a messy reality sound too smooth. For autonomous operations to actually land, every hard problem is still there: reliability, accountability, and humans trusting a probabilistic system. No slide can do that work for them. But even after the discount, I still think the direction holds up: when systems turn probabilistic and AI starts operating them on our behalf, the old “humans staring at dashboards” paradigm really isn’t enough anymore. That doesn’t hinge on Datadog’s stock price; it’s a reality this whole industry can’t get around. If I’m allowed only one line: The old observability helped people see and fix deterministic failures faster inside a dynamic cloud environment; observability in the AI era faces a system that is dynamic, stochastic, and operated in part by AI agents, and its center of gravity is shifting from “human-assisted diagnosis” to “model-driven autonomous operations.” Datadog tells this turn most completely, but the question isn’t its alone. For everyone who builds platforms, runs ops, or works on infrastructure, it’s worth thinking through early, the same question: When the system starts to turn uncertain, and machines start acting on our behalf, do we still need to “keep an eye on it” — and how?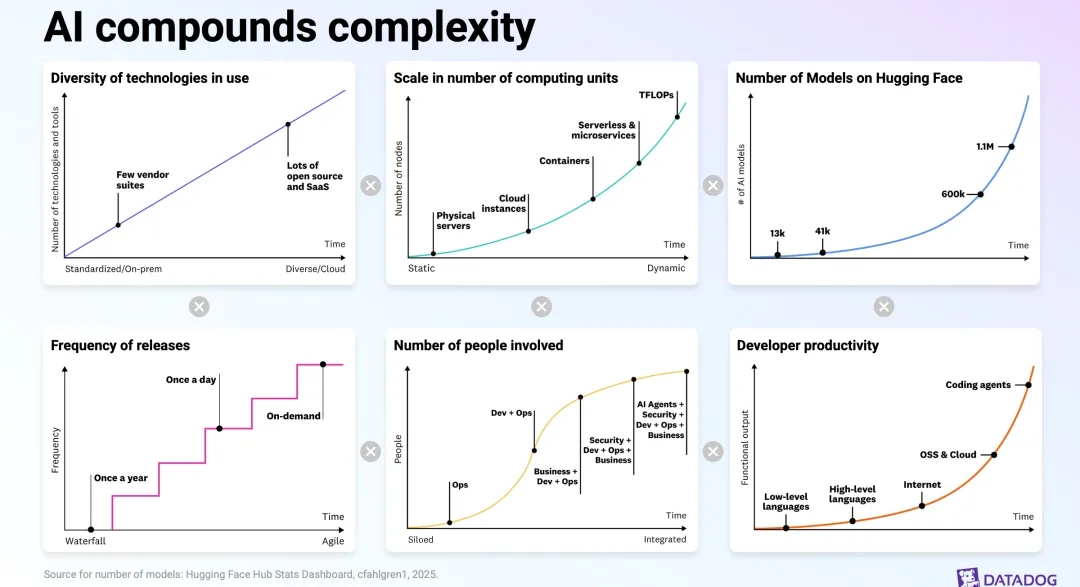
Back to first principles: observability has always been a business of fighting complexity
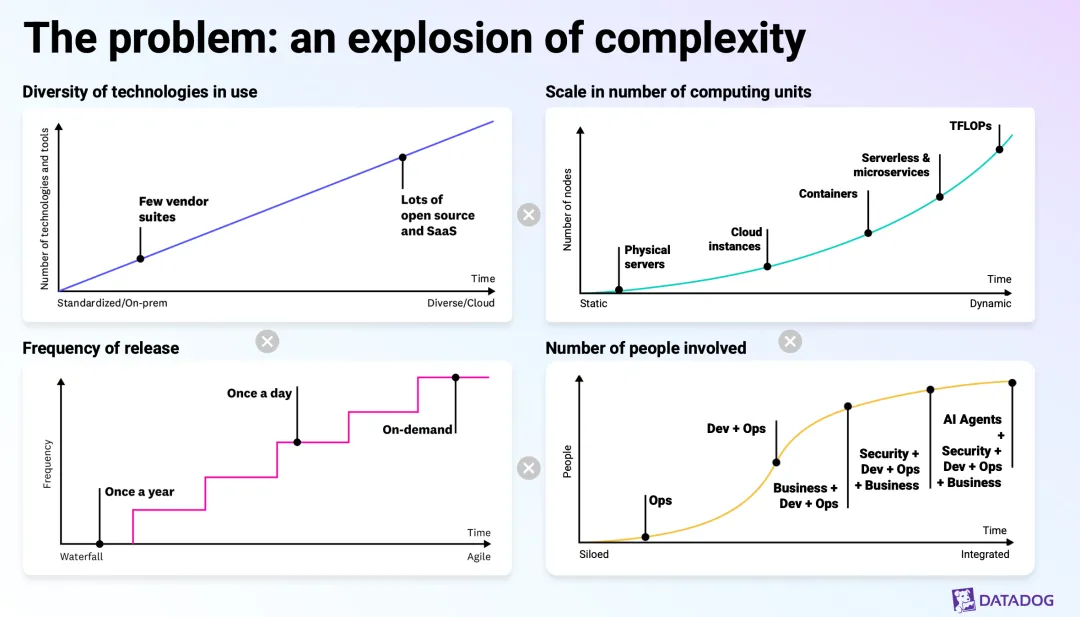
What AI really changes isn’t “one more thing to monitor” — it’s the nature of the system
The second change: it’s no longer only humans who operate the system
The third change: the “reader” of the data goes from human to model

What gives it the standing to say all this

A reality check: this is, after all, an investor narrative
In closing
References