The Three Pillars of Observability: A History No One Planned (Part 1 of 2)
Table of Contents
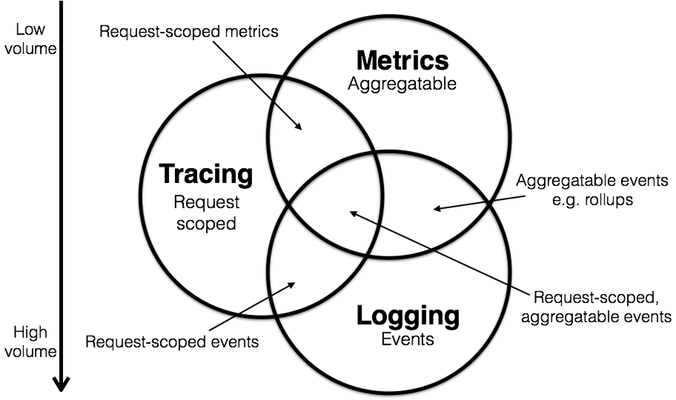
Today we treat metrics, logging, and tracing as the natural structure of observability. But it wasn't designed; it grew. Part 1, on how it split apart (2010–2017). Today we treat metrics, logging, and tracing as the natural structure of observability. But it wasn’t designed; it grew. This is Part 1, on how it split apart (2010–2017). “Metrics, logging, tracing.” Anyone who talks about observability can rattle them off. The phrase “three pillars” rolls off the tongue so easily that it starts to sound like a law of nature, as if observability was always meant to divide into these three parts from day one. But no one designed it that way. No committee ever convened to decide that observability should consist of three kinds of signals. These three things were built independently, over more than a decade, by three completely different groups of people, for three completely different problems. By the time anyone stepped back to look, they had already grown into three separate trees, each with its own root system, none able to budge the others. I want to spend two parts tracing how the ground came to be divided this way. Not as an exercise in archaeology, but because if you want to understand why “unified observability” has been talked about for so many years without ever really being achieved, you first have to see clearly why it split apart in the first place. The split wasn’t an accident: behind every crack was a reason that made sense at the time. This part covers the split itself (2010–2017); the next covers the people who began trying to put it back together (2018 onward). Let’s get the timeline straight first. These three kinds of signals didn’t appear all at once, and the order wasn’t random: each one had to wait for the architecture of its day to make its problem urgent enough to be worth solving. Metrics came first. The lineage of time-series monitoring tools traces all the way back to RRDtool (1999), through Graphite (born at Orbitz in 2006, open-sourced in 2008), and on to SoundCloud’s Prometheus in 2012. This line has always solved the same problem: is the system healthy right now? What operations teams want is a pulse they can glance at any time: CPU usage, QPS, whether the error rate is spiking. The data involved is written at high frequency, has low cardinality, can be sampled at regular intervals, and stays cheap to retain long-term through downsampling. Time Series Databases were tailor-made for exactly this problem. They don’t care about any single data point; they care about the trend. Logging came next. Splunk, founded in 2003, turned “searching logs” into a business; Elasticsearch shipped in 2010 and later joined Logstash and Kibana to form the ELK stack. Logging answers a different question: what actually happened? When a developer is chasing down a specific failure, what they need is the ability to run full-text search, filter by arbitrary fields, and find their way to the exact line where things broke. That set of needs maps to an inverted index, a data shape and storage approach with almost no overlap with metrics. One wants to aggregate; the other wants to locate. Tracing came last, and came reluctantly. Google published the Dapper paper in 2010 but never open-sourced the code; what actually lit the fire was Zipkin, which Twitter open-sourced in June 2012, the first usable open-source distributed tracing system. Uber’s Jaeger started internally in 2015 and wasn’t open-sourced until 2017. Tracing arrived late not because no one had thought of it, but because it depended on a precondition. Distributed systems and microservice architectures had to become widespread enough first, before “how exactly does a single request flow across dozens of services” became a real problem. Its data is a causally linked tree of spans, neither the time-series points of metrics nor the text streams of logs, but a third, entirely different data model. Put these three lines side by side and two things stand out. First, the sequence tracks the evolution of the architecture itself: metrics when a single machine could break, logging when systems grew big enough that you had to search to find anything, tracing when one request began crossing dozens of services. Second, they aren’t three views of the same system, but three independent answers to three independent problems. Metrics answer “is it healthy”; logging answers “what happened”; tracing answers “where is it slow, which service is the bottleneck.” Different problems, so the tools built for them naturally turned out to look different. If it were only a matter of arriving at different times, merging them later wouldn’t be hard. The trouble is that the engineering constraints of these three kinds of data conflict sharply with one another, and each was pushed to an extreme. In almost every row of this table, the three columns are fighting each other. Metrics want to be optimized for aggregation, logging for search, tracing for point lookups by ID and tree traversal. For one system to do all three well, under the technical conditions of the early 2010s, was essentially pushing uphill against engineering gravity: the optimization you make for one kind is often a burden on another. So three separate systems weren’t a product of shortsightedness. At the time, building them separately was simply easier and more likely to succeed. Letting each one chew through its own problem was more pragmatic than chasing grand unification from the start. This point comes up again later; it explains why the idea of “unification,” even though people raised it early on, stayed an idea for so long. The technical split had its reasons. But what truly hardened that crack — set it into a wall no one could push over — was commerce. Splunk got its start selling log search, and logs are a high-margin business; Datadog’s early foothold was metrics monitoring (infrastructure monitoring); New Relic made its name on APM (at its core, distributed tracing). Three companies, each staking out one plot of land among the three pillars. Those plots were almost drawn for them. The three signals were already three data shapes, so the technical seam doubled neatly as the market boundary. No one had to sit down and agree on how to divide the territory; each vendor simply defending its strongest ground was enough for the carve-up to take shape on its own. Here’s a piece of logic few state outright. For these vendors, the division itself is the moat. Get metrics right to the extreme, and customers are locked into your metrics ecosystem. Unifying would mean giving up the ground you know best and have the most pricing power over, then going to fight all over again on a larger battlefield where you may not hold the advantage. No incumbent has any incentive to do this on its own. The split wasn’t only on the supply side, either; buyers were carved up the same way. Infrastructure monitoring usually sat with the infrastructure and SRE teams, APM belonged to the developers, and logs often landed with security, or even the big-data team. The customer’s budget already came in three separate pockets, and half of why vendors stayed in their lanes was the org chart on the demand side feeding them that way. And so a rather ironic situation took shape: hard to unify technically, and no one willing to unify commercially. These forces compounded, until the three pillars drifted from “an engineering choice of the moment” into “the industry’s default worldview.” By the time the cloud-native era’s data explosion made unification genuinely worth its cost, the wall had already been poured thick. The one apparent exception proves the rule. Datadog did eventually pull all three together under “full-stack observability” — but it got there by acquisition and years of building, and only well after the walls had been poured. Unifying was costly enough that it took a later, well-capitalized incumbent to buy its way across. How it did, and what that cost, is a story for Part 2. By 2017, someone finally drew this already-existing split out explicitly. A bit earlier, the 2013 blog post Observability at Twitter counts as one of software’s earlier attempts to discuss observability as a complete concept. Twitter was breaking its monolith into microservices at the time and realized that a single type of monitoring data wasn’t enough, but there was no clean carving into “three kinds of signals” yet. The real carving came from Peter Bourgon. In February 2017, having just attended that year’s Distributed Tracing Summit (the room included people from AWS/X-Ray, OpenZipkin, OpenTracing, Instana, Datadog, and others), he came back and wrote a blog post titled Metrics, tracing, and logging. One question being argued at the summit was whether a tracing system should also handle logging, and where the boundary sat. Bourgon felt everyone was going in circles for lack of a shared vocabulary, so he drew a Venn diagram to clarify the domains of metrics, tracing, and logging and how they overlap. Source: Peter Bourgon, Metrics, tracing, and logging (2017). That diagram was the conceptual origin of what later became the “three pillars” framework. But one detail needs to be made clear, because it happens to be a quiet thread running through this series. Bourgon’s intent at the time was only to clarify vocabulary, not to erect a framework. What he was handing the room was a shared vocabulary, not a blueprint — a way to talk about the problem, not a doctrine on “how observability ought to be architected.” The more ceremonial phrase “three pillars” only solidified later, as discussions like Cindy Sridharan’s Distributed Systems Observability popularized it, and industry vendors seized on the framework to carve up their respective markets. In other words, a tool meant to clarify a concept got taken by the industry as a blueprint for “how things should be.” Bourgon drew the diagram to help people speak more precisely; instead it got nailed to the wall and became a map with three vendors each holding a corner. The mismatch wasn’t his intent, but it did shape the industry’s direction for nearly a decade after. At this point in the story, you’d probably assume Bourgon was the person who split observability into three. But there’s a twist. A year and a half later, in August 2018, he wrote another blog post. This time he didn’t keep clarifying boundaries; instead he asked a bigger question. If metrics, tracing, and logging are essentially the same batch of raw events, shaped into different forms by different modes of consumption, then in theory, could there be a single system that ingests raw events at the entry point and then routes them by “shape” into metrics, tracing, and logging? He gave this idea a name: the über-system, a single unifying super-system. That was 2018. At the time this line of reasoning was just a small section in a blog post, and it caused no stir. The same person who drew the three-pillars Venn diagram had, almost in passing, offered another possibility (“maybe it shouldn’t be split into three at all”), and the industry caught the former while all but ignoring the latter. The conditions for this idea to actually become real were nearly eight years away. In the next part, we’ll pick up from this overlooked about-face: how, after 2018, seeds of unification began sprouting in several places at once, and why not one of those sprouts ever truly grew into a tree.
The three signals emerged one at a time
Why they were bound to look different
Dimension Metrics Logging Tracing Data shape Time-series points Text / structured records Span tree Write pattern High-frequency, small High-volume batches Moderate frequency Query pattern Aggregation, downsampling Full-text search, filtering Point lookup by trace_id + causal analysis Cardinality Low (traditionally) Medium-high High (trace_id) Retention Long (downsamplable) Short to medium Medium Common backends then Time-series store Inverted index Cassandra / ES, etc. Then commerce cast the crack into a wall
The person who gave it all a name
An overlooked about-face
References