The Three Pillars of Observability: The Unification That Never Quite Arrived (Part 2 of 2)
Table of Contents
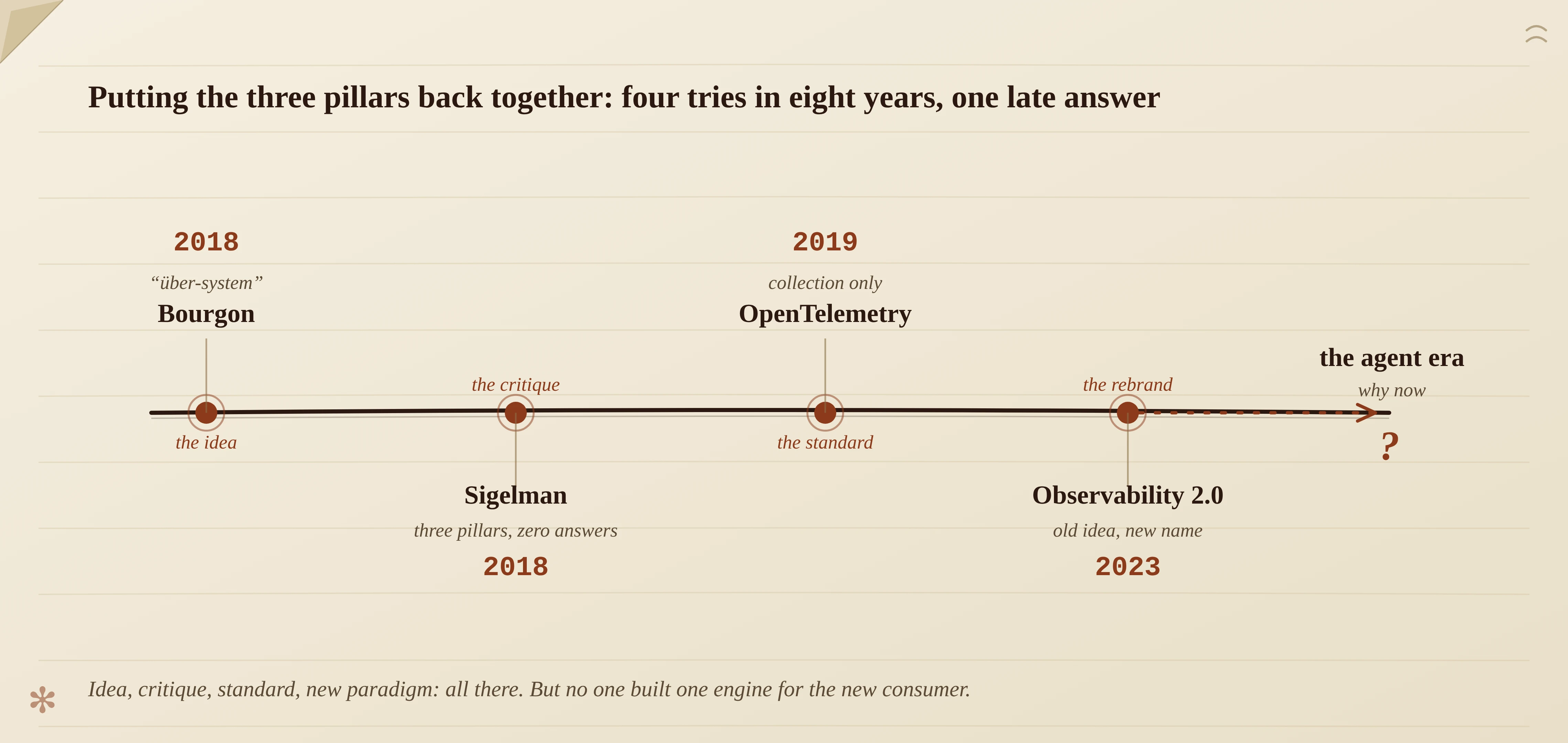
Part 1 was about how the three pillars split apart. This part is about how many smart people, starting in 2018, tried to put them back together — what they actually built, and why none of it quite reached the finish line. Part 1 was about how the three pillars split apart. This part is about how many smart people, starting in 2018, tried to put them back together — what they actually built, and why none of it quite reached the finish line. At the end of Part 1 I left a hook: in August 2018, Peter Bourgon, the same person who drew the three-pillars Venn diagram, wrote another blog post. In it he imagined the opposite: a single, unified “super-system.” This part starts from that overlooked thought experiment. It’s worth spelling out, because nearly every attempt to “unify observability” over the next eight years was, in essence, a rediscovery of the reasoning Bourgon laid out back then. Most people just didn’t know he’d gotten there first. Bourgon’s 2018 post is called Observability signals[1]. His starting point is counterintuitive: metrics, tracing, and logging aren’t three fundamentally different things. They’re three different ways observation data gets consumed, and it’s those consumption patterns that, in turn, dictate how we produce, transport, and store the corresponding signals. Put differently: the three pillars aren’t three natures of the data. They’re three habits of the people using it. Following that thread, he arrives at the key idea. If that’s the case, then in principle you should be able to build a single, unified system (he called it an über-system). The write path ingests raw events, then de-muxes them by “shape” into metrics, traces, and logs, optimizes each accordingly, and stores them in the appropriate backend. Reading this, you might think: isn’t this exactly what everyone talks about now? Yes, it is. The difference is that Bourgon had the whole logic worked out in 2018, and in an unusually clear-eyed way. He didn’t treat unification as a product slogan, but as a conclusion derived from the nature of the data itself. And yet the idea barely made a ripple at the time. The same person who drew the three-pillars Venn diagram had, almost in passing, offered the opposite answer: maybe it shouldn’t be split into three at all. The industry eagerly caught the former and all but ignored the latter. What’s striking is that Bourgon wasn’t the only one pushing on the three pillars in 2018. That December, at KubeCon North America (Seattle), Ben Sigelman gave a talk with a deliberately provocative title: Three Pillars, Zero Answers: We Need to Rethink Observability[2]. Sigelman co-authored Google’s Dapper paper and co-founded OpenTracing and, later, OpenTelemetry. He’s no outsider; he helped build these pillars with his own hands. His critique was concrete, not hand-waving: Put the two together and 2018 looks like a strange hinge year. The two people who understood this stuff best, one arguing from the nature of the data that it should be unified (Bourgon), the other arguing from cost and flaws that the three pillars answer nothing (Sigelman), pushed against the same orthodoxy, from two directions, in the same year. And Sigelman didn’t just talk. He went on to found Lightstep, putting real money behind his own vision of a different kind of observability product. So the critique wasn’t merely voiced by the person most qualified to make it. He went and tried it. And then? And then the industry kept paying for three pillars for years. The turning point looked like it arrived in 2019. That May at KubeCon, OpenCensus (Google-led, metrics-leaning) and OpenTracing (community-led, tracing-leaning) announced they would merge into OpenTelemetry (OTel) and enter the CNCF[3]. Two formerly competing standards became one, with a seed governance committee drawn from Google, Lightstep, Microsoft, and Uber. This was the first time “unification” truly landed at the standards layer. But here’s the cold water, and this cold water is the key to the whole series: what OTel unified was collection and protocol, not storage and query. It lets you produce telemetry with one SDK and one set of semantics, then ship it to whatever backend you like. But once the data lands, the three stores are still three stores, and querying across three systems is still querying across three systems. OTel connected the upstream pipe; downstream, the three pools are still three pools. OTel’s most underrated legacy is actually something else: semantic conventions. What (A timely footnote: just a week before this piece was written, on May 21, 2026, OTel announced its graduation from the CNCF, second only to Kubernetes in project velocity[4]. From a 2019 merger born to heal a split, to today’s de facto standard, it took a full seven years.) Fast-forward to late 2023. Honeycomb’s CTO, Charity Majors, coined a new term: Observability 2.0[5]. Her definition is crisp. Observability 1.0 is the three pillars: multiple sources of truth, data scattered across a pile of tools and formats, stitched together by engineers eyeballing whether this spike lines up with that one. Observability 2.0 has a single source of truth, arbitrarily wide structured events (wide events), and metrics, traces, and the rest are just views derived from that one body of data. Pause for a second. Doesn’t this feel familiar? It’s the same line of thinking as Bourgon’s 2018 über-system reasoning: raw events are primary, the three pillars are secondary. Bourgon comes at it from “demux on the write side into different backends,” Charity from “derive every view from one wide event.” Different angles, but they reject the same thing: the three-pillars worldview where you have to instrument, store, and pay for everything separately. Six years in between. And this time, the seeds really were sprouting everywhere. Charity has a sharp observation: nearly every observability startup founded after 2021 that’s still alive uses a unified-storage model, with wide structured events stored in a columnar database (often ClickHouse), OTel-native. Nobody’s building “a cheaper Datadog” (three pillars, many sources of truth) anymore; everyone’s building “a cheaper Honeycomb.” To be fair, the paradigm isn’t without critics, and I should give the full picture. The most common objection is cost. Wide events keep all that high cardinality × high dimensionality, so there’s more data per request than any single pillar, and a distributed system produces these events in multiplied volume, so the bill can easily run away. And in practice, metrics stay irreplaceable: they’re often an order of magnitude cheaper than wide events, cheap enough that you can’t actually swap them out for wide events. Even the “2.0” name is contested. Charity herself later had reservations about the label, the community floated an “Observability 3.0,” and some are simply tired of marketing by semantic versioning. So when I cite Observability 2.0, I’m not treating it as a settled, victorious conclusion. I’m treating it as a high-profile return of Bourgon’s line of thought, a signal that puts “raw events are what’s primary” back on the table. Whether it’s right, and what to call it, is a separate matter. By now you’re probably asking: the idea exists (Bourgon), the critique exists (Sigelman), the standard exists (OTel), the new paradigm exists (Observability 2.0), and there’s a pile of startups. So was “unification” ever actually done? Let me be honest about one fact first. If what you’re asking is “has anyone put all three signals into one columnar store, queried them uniformly, and held up at production scale,” then the answer is yes, and more than one team has. SigNoz stores metrics, logs, and traces in a single ClickHouse, OTel-native, and teams already run it in production at serious scale (thousands of hosts, 10+ TB a day) to replace commercial tools. The more telling case is ClickStack: launched after ClickHouse Inc. acquired HyperDX in 2025, it bundles an OTel Collector, ClickHouse, and a query UI into an open-source, full-stack package, and its UI is built around a unified, cross-signal search rather than separate per-signal tabs. Add Honeycomb, which bet on wide events years ago and is closest to the end state in principle, plus that whole crop of post-2021 startups mostly on unified columnar storage, and “three signals, one columnar store” is fast becoming a solved, even commoditized, thing at the storage and experience layers. So if I stood here and yelled “nobody has done unified storage,” I’d be denying what’s in plain sight. Then why do I still say this hasn’t truly reached the finish line? Because when you lay these solutions side by side, they share three easily overlooked traits. First, the ones that genuinely achieve single storage (SigNoz, ClickStack) are almost all built on the same general-purpose engine: ClickHouse. It’s a columnar store designed for general-purpose OLAP, borrowed by one observability backend after another. It’s genuinely good, but it was borrowed, not designed around the distinct access patterns of the three signals. That distinction doesn’t matter when the data is small; once scale climbs and the workload gets messy, the cost starts to show. Exactly where it shows, I’ll save for the final part. Second, the other popular path, Grafana’s LGTM stack, doesn’t even unify the storage layer. Loki for logs, Tempo for traces, Mimir for metrics, Grafana for visualization: on screen the three signals sit side by side and it looks integrated, but pry it open and underneath are still several independent systems, merely “stitched” together at the top UI layer. That’s unification at the experience layer, not the engine layer. Third, the most important and most hidden point: all of this was built for one and the same consumer, a human. Whether it’s SigNoz’s explorer, ClickStack’s unified search, or Honeycomb’s query interface, the underlying assumption is that an engineer is sitting in front of a screen, querying linearly, thinking while staring at a dashboard, correlating the three signals in their own head. What they optimize for is making it smoother for that person to look at. And that whole set of assumptions is quietly being overturned by a new consumer. This consumer is not human. On top of that, the three-pillars framework was locked in by commerce long ago. As one piece on Observability 2.0 put it bluntly, back when Bourgon drew observability as a Venn diagram, vendors quickly used the framework to carve up the market[6]. This is the same thing I described in Part 1, commerce setting the crack into a wall, just confirmed again from another angle. So after sorting through these eight years, the real picture isn’t “nobody built unified storage.” It’s something subtler. Unified storage got built, even productized. But almost all of it sits on a borrowed, general-purpose engine; all of it was designed for human eyes; and all of it took shape before a new era arrived, an era in which the thing querying observability data will no longer be mainly human. Nobody has redesigned that unified engine for this new consumer, starting from the access patterns of the three signals. The technical pieces have fallen into place one by one over these years, and new players have every incentive to flip the table. So the holdup isn’t really technical, and it isn’t purely commercial. What, then, pushed this from “done, but a breath short” to “has to be redone”? My answer: not cloud-native, not cost. It’s the arriving agent era. When the querying end switches from human to agent, the meaning of “unification” gets rewritten from the ground up, and that’s exactly the question none of the past eight years’ solutions had time to answer. Now that the history’s told, the next piece takes it up: why now. Ben Sigelman, Three Pillars, Zero Answers: We Need to Rethink Observability, KubeCon NA 2018 (Seattle, December); expanded into a Medium piece in early 2020. ↩ OpenTelemetry: The Merger of OpenCensus and OpenTracing (Google Open Source Blog, 2019-05-21); see also A brief history of OpenTelemetry (so far), CNCF, 2019-05-21 — “the seed governance and technical committees are composed of representatives from Google, LightStep, Microsoft, and Uber.” ↩ CNCF Announces OpenTelemetry’s Graduation (announced 2026-05-21; the CNCF project page records the graduation date as 2026-05-11). The announcement states OTel reached “the second-highest project velocity among over 240 projects… second only to Kubernetes.” ↩ The “Observability 2.0” framing (O11y 1.0 vs 2.0) first took shape in Charity Majors’s late-2023 writing (charity.wtf, 2023-12-22, following her October 2023 thread on “losing the battle to define observability”); the fuller exposition is There Is Only One Key Difference Between Observability 1.0 and 2.0 (2024). ↩
The most underrated post
2018: the two people who understood it best both pushed back, in the same year
2019: unification lands for the first time, but only at the collection layer
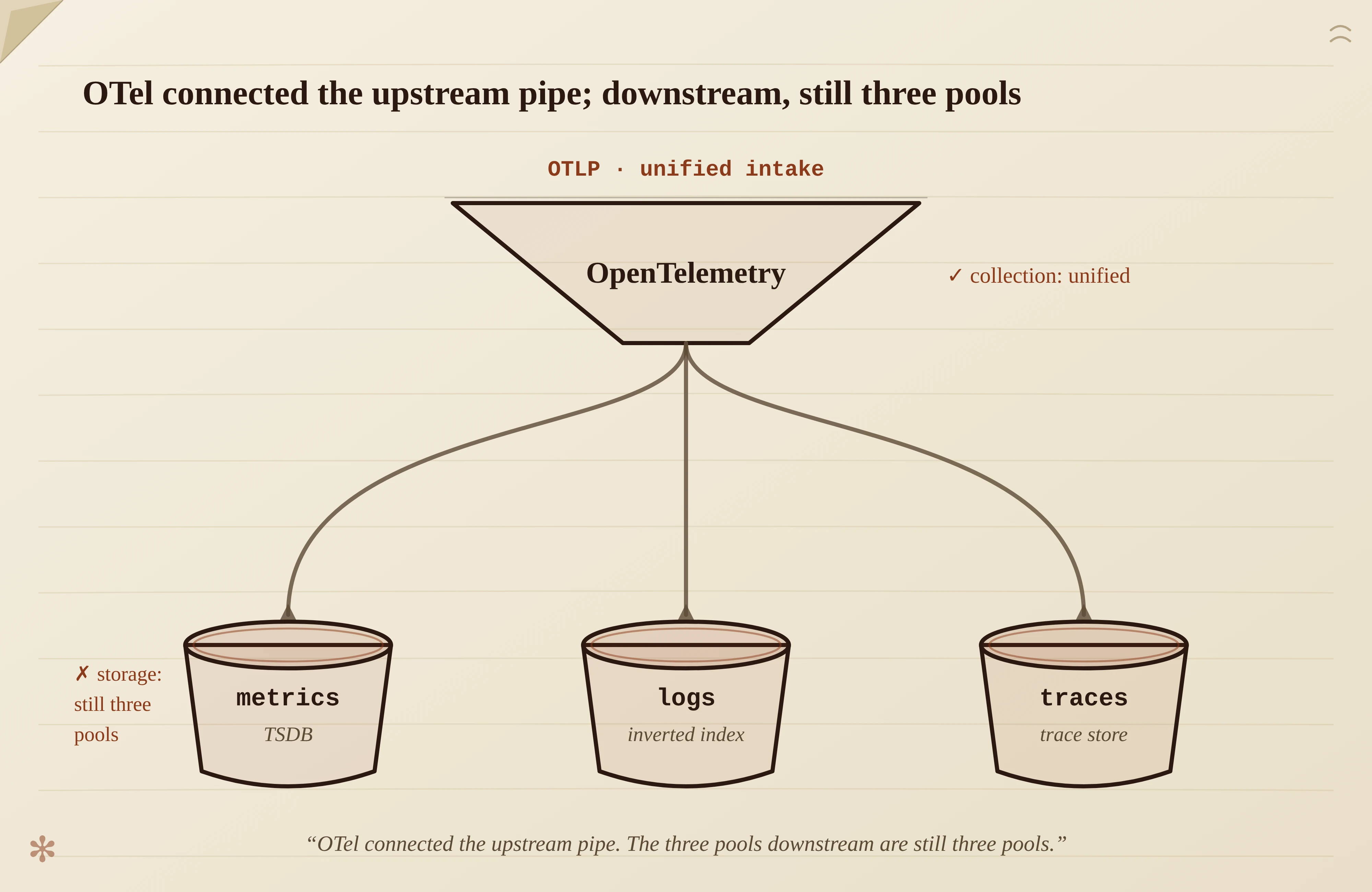
http.request.method should be called, which standard fields a database-call span should carry, these names got distilled into an industry consensus. At the time everyone treated it as the unglamorous work of aligning field names, but the payoff wouldn’t really show up until years later. I’ll leave this thread buried here; a follow-up piece explains why it suddenly matters.2023: the same idea comes back under a new name
So, was unification ever actually done?
References